The word “automation” has become a buzzword in pop culture. It conjures things like self-driving cars, robotic assistants, and factory assembly lines. They don’t think about automation for software testing. In fact, many non-software folks are surprised to hear that what I do is “automation.”
The word “automation” also carries a connotation of “full” automation with zero human intervention. Unfortunately, most of our automated technologies just aren’t there yet. For example, a few luxury cars out there can parallel-park themselves, and Teslas have some cool autopilot capabilities, but fully-autonomous vehicles do not yet exist. Self-driving cars need several more years to perfect and even more time to become commonplace on our roads.
Software testing is no different. Even when test execution is automated, test development is still very manual. Ironic, isn’t it? Well, I think the day of “full” test automation is quickly approaching. We are riding the crest of the next great wave: autonomous testing. It’ll arrive long before cars can drive themselves. Like previous waves, it will fundamentally change how we, as testers, approach our craft.
Let’s look at the past two waves to understand this more deeply. You can watch the keynote address I delivered at Future of Testing: Frameworks 2022, or you can keep reading below.

Before Automation
In their most basic form, tests are manual. A human manually exercises the behavior of the software product’s features and determines if outcomes are expected or erroneous. There’s nothing wrong with manual testing. Many teams still do this effectively today. Heck, I always try a test manually before automating it. Manual tests may be scripted in that they follow a precise, predefined procedure, or they may be exploratory in that the tester relies instead on their sensibilities to exercise the target behaviors.
Testers typically write scripted tests as a list of steps with interactions and verifications. They store these tests in test case management repositories. Most of these tests are inherently “end-to-end:” they require the full product to be up and running, and they expect testers to attempt a complete workflow. In fact, testers are implicitly incentivized to include multiple related behaviors per test in order to gain as much coverage with as little manual effort as possible. As a result, test cases can become very looooooooooooong, and different tests frequently share common steps.
Large software products exhibit countless behaviors. A single product could have thousands of test cases owned and operated by multiple testers. Unfortunately, at this scale, testing is slooooooooow. Whenever developers add new features, testers need to not only add new tests but also rerun old tests to make sure nothing broke. Software is shockingly fragile. A team could take days, weeks, or even months to adequately test a new release. I know – I once worked at a company with a 6-month-long regression testing phase.
Slow test cycles forced teams to practice Waterfall software development. Rather than waste time manually rerunning all tests for every little change, it was more efficient to bundle many changes together into a big release to test all at once. Teams would often pipeline development phases: While developers are writing code for the features going into release X+1, testers would be testing the features for release X. If testing cycles were long, testers might repeat tests a few times throughout the cycle. If testing cycles were short, then testers would reduce the number of tests to run to a subset most aligned with the new features. Test planning was just as much work as test execution and reporting due to the difficulty in judging risk-based tradeoffs.

Slow manual testing was the bane of software development. It lengthened time to market and allowed bugs to fester. Anything that could shorten testing time would make teams more productive.
The First Wave: Manual Test Conversion
That’s when the first wave of test automation hit: manual test conversion. What if we could implement our manual test procedures as software scripts so they could run automatically? Instead of a human running the tests slowly, a computer could run them much faster. Testers could also organize scripts into suites to run a bunch of tests at one time. That’s it – that was the revolution. Let software test software!
During this wave, the main focus of automation was execution. Teams wanted to directly convert their existing manual tests into automated scripts to speed them up and run them more frequently. Both coded and codeless automation tools hit the market. However, they typically stuck with the same waterfall-minded processes. Automation didn’t fundamentally change how teams developed software, it just made testing better. For example, during this wave, running automated tests after a nightly build was in vogue. When teams would plan their testing efforts, they would pick a few high-value tests to automate and run more frequently than the rest of the manual tests.

Unfortunately, while this type of automation offered big improvements over pure manual testing, it had problems. First, testers still needed to manually trigger the tests and report results. On a typical day, a tester would launch a bunch of scripts while manually running other tests on the side. Second, test scripts were typically very fragile. Both tooling and understanding for good automation had not yet matured. Large end-to-end tests and long development cycles also increased the risk of breakage. Many teams gave up attempting test automation due to the maintenance nightmare.
The first wave of test automation was analogous to cars switching from manual to automatic transmissions. Automation made the task of driving a test easier, but it still required the driver (or the tester) to start and stop the test.
The Second Wave: CI/CD
The second test automation wave was far more impactful than the first. After automating the execution of tests, focus shifted to automating the triggering of tests. If tests are automated, then they can run without any human intervention. Therefore, they could be launched at any time without human intervention, too. What if tests could run automatically after every new build? What if every code change could trigger a new build that could then be covered with tests immediately? Teams could catch bugs as soon as they happen. This was the dawn of Continuous Integration, or “CI” for short.
Continuous Integration revolutionized software development. Long Waterfall phases for coding and testing weren’t just passé – they were unnecessary. Bite-sized changes could be independently tested, verified, and potentially deployed. Agile and DevOps practices quickly replaced the Waterfall model because they enabled faster releases, and Continuous Integration enabled Agile and DevOps. As some would say, “Just make the DevOps happen!”
The types of tests teams automated changed, too. Long end-to-end tests that covered “grand tours” with multiple behaviors were great for manual testing but not suitable for automation. Teams started automating short, atomic tests focused on individual behaviors. Small tests were faster and more reliable. One failure pinpointed one problematic behavior.
Developers also became more engaged in testing. They started automating both unit tests and feature tests to be run in CI pipelines. The lines separating developers and testers blurred.
Teams adopted the Testing Pyramid as an ideal model for test count proportions. Smaller tests were seen as “good” because they were easy to write, fast to execute, less susceptible to flakiness, and caught problems quickly. Larger tests, while still important for verifying workflows, needed more investment to build, run, and maintain. So, teams targeted more small tests and fewer large tests. You may personally agree or disagree with the Testing Pyramid, but that was the rationale behind it.
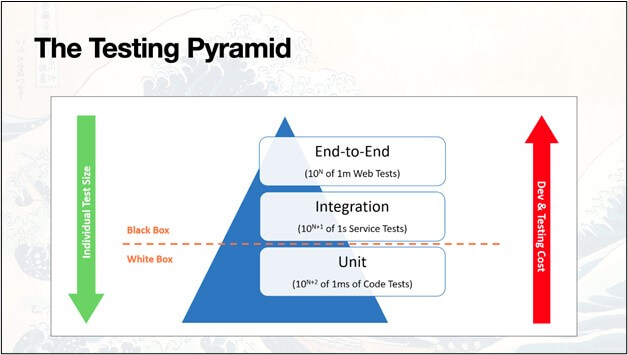
While the first automation wave worked within established software lifecycle models, the second wave fundamentally changed them. The CI revolution enabled tests to run continuously, shrinking the feedback loop and maximizing the value that automated tests could deliver. It gave rise to the SDET, or Software Development Engineer in Test, who had to manage tests, automation, and CI systems. SDETs carried more responsibilities than the automation engineers of the first wave.
If we return to our car analogy, the second wave was like adding cruise control. Once the driver gets on the highway, the car can just cruise on its own without much intervention.
Unfortunately, while the second wave enabled teams to multiply the value they can get out of testing and automation, it came with a cost. Test automation became full-blown software development in its own right. It entailed tools, frameworks, and design patterns. The continuous integration servers became production environments for automated tests. While some teams rose to the challenge, many others struggled to keep up. The industry did not move forward together in lock-step. Test automation success became a gradient of maturity levels. For some teams, success seemed impossible to reach.
Attempts at Improvement
Now, these two test automation waves I described do not denote precise playbooks every team followed. Rather, they describe the general industry trends regarding test automation advancement. Different teams may have caught these waves at different times, too.
Currently, as an industry, I think we are riding the tail end of the second wave, rising up to meet the crest of a third. Continuous Integration, Agile, and DevOps are all established practices. The innovation to come isn’t there.
Over the past years, a number of nifty test automation features have hit the scene, such as screen recorders and smart locators. I’m going to be blunt: those are not the next wave, they’re just attempts to fix aspects of the previous waves.
- Screen recorders and visual step builders have been around forever, it seems. Although they can help folks who are new to automation or don’t know how to code, they produce very fragile scripts. Whenever the app under test changes its behavior, testers need to re-record tests.
- Self-healing locators don’t deliver much value on their own. When a locator breaks, it’s most likely due to a developer changing the behavior on a given page. Behavior changes require test step changes. There’s a good chance the target element would be changed or removed. Besides, even if the target element keeps its original purpose, updating its locator is a super small effort.
- Visual locators – ones that find elements based on image matching instead of textual queries – also don’t deliver much value on their own. They’re different but not necessarily “better.” The one advantage they do offer is finding elements that are hard to locate with traditional locators, like a canvas or gaming objects. Again, the challenge is handling behavior change, not element change.
You may agree or disagree with my opinions on the usefulness of these tools, but the fact is that they all share a common weakness: they are vulnerable to behavioral changes. Human testers must still intervene as development churns.
These tools are akin to a car that can park itself but can’t fully drive itself. They’re helpful to some folks but fall short of the ultimate dream of full automation.
The Third Wave: Autonomous Testing
The first two waves covered automation for execution and scheduling. Now, the bottleneck is test design and development. Humans still need to manually create tests. What if we automated that?
Consider what testing is: Testing equals interaction plus verification. That’s it! You do something, and you make sure it works correctly. It’s true for all types of tests: unit tests, integration tests, end-to-end tests, functional, performance, load; whatever! Testing is interaction plus verification.

During the first two waves, humans had to dictate those interactions and verifications precisely. What we want – and what I predict the third wave will be – is autonomous testing, in which that dictation will be automated. This is where artificial intelligence can help us. In fact, it’s already helping us.
Applitools has already mastered automated validation for visual interfaces. Traditionally, a tester would need to write several lines of code to functionally validate behaviors on a web page. They would need to check for elements’ existence, scrape their texts, and make assertions on their properties. There might be multiple assertions to make – and other facets of the page left unchecked. Visuals like color and position would be very difficult to check. Applitools Eyes can replace almost all of those traditional assertions with single-line snapshots. Whenever it detects a meaningful change, it notifies the tester. Insignificant changes are ignored to reduce noise.
Automated visual testing like this fundamentally simplifies functional verification. It should not be seen as an optional extension or something nice to have. It automates the dictation of verification. It is a new type of functional testing.
The remaining problem to solve is dictation of interaction. Essentially, we need to train AI to figure out proper app behaviors on its own. Point it at an app, let it play around, and see what behaviors it identifies. Pair those interactions with visual snapshot validation, and BOOM – you have autonomous testing. It’s testing without coding. It’s like a fully-self-driving car!
Some companies already offer tools that attempt to discover behaviors and formulate test cases. Applitools is also working on this. However, it’s a tough problem to crack.
Even with significant training and refinement, AI agents still have what I call “banana peel moments:” times when they make surprisingly awful mistakes that a human would never make. Picture this: you’re walking down the street when you accidentally slip on a banana peel. Your foot slides out from beneath you, and you hit your butt on the ground so hard it hurts. Everyone around you laughs at both your misfortune and your clumsiness. You never saw it coming!
Banana peel moments are common AI hazards. Back in 2011, IBM created a supercomputer named Watson to compete on Jeopardy, and it handily defeated two of the greatest human Jeopardy champions at that time. However, I remember watching some of the promo videos at the time explaining how hard it was to train Watson how to give the right answers. In one clip, it showed Watson answering “banana” to some arbitrary question. Oops! Banana? Really?

While Watson’s blunder was comical, other mistakes can be deadly. Remember those self-driving cars? Tesla autopilot mistakes have killed at least a dozen people since 2016. Autonomous testing isn’t a life-or-death situation like driving, but testing mistakes could be a big risk for companies looking to de-risk their software releases. What if autonomous tests miss critical application behaviors that turn out to crash once deployed to production? Companies could lose lots of money, not to mention their reputations.
So, how can we give AI for testing the right training to avoid these banana peel moments? I think the answer is simple: set up AI for testing to work together with human testers. Instead of making AI responsible for churning out perfect test cases, design the AI to be a “coach” or an “advisor.” AI can explore an app and suggest behaviors to cover, and the human tester can pair that information with their own expertise to decide what to test. Then, the AI can take that feedback from the human tester to learn better for next time. This type of feedback loop can help AI agents not only learn better testing practices generally but also learn how to test the target app specifically. It teaches application context.
AI and humans working together is not just a theory. It’s already happened! Back in the 90s, IBM built a supercomputer named Deep Blue to play chess. In 1996, it lost 4-2 to grandmaster and World Chess Champion Garry Kasparov. One year later, after upgrades and improvements, it defeated Kasparov 3.5-2.5. It was the first time a computer beat a world champion at chess. After his defeat, Kasparov had an idea: What if human players could use a computer to help them play chess? Then, one year later, he set up the first “advanced chess” tournament. To this day, “centaurs,” or humans using computers, can play at nearly the same level as grandmasters.

I believe the next great wave for test automation belongs to testers who become centaurs – and to those who enable that transformation. AI can learn app behaviors to suggest test cases that testers accept or reject as part of their testing plan. Then, AI can autonomously run approved tests. Whenever changes or failures are detected, the autonomous tests yield helpful results to testers like visual comparisons to figure out what is wrong. Testers will never be completely removed from testing, but the grindwork they’ll need to do will be minimized. Self-driving cars still have passengers who set their destinations.
This wave will also be easier to catch than the first two waves. Testing and automation was historically a do-it-yourself effort. You had to design, automate, and execute tests all on your own. Many teams struggled to make it successful. However, with the autonomous testing and coaching capabilities, AI testing technologies will eliminate the hardest parts of automation. Teams can focus on what they want to test more than how to implement testing. They won’t stumble over flaky tests. They won’t need to spend hours debugging why a particular XPath won’t work. They won’t need to wonder what elements they should and shouldn’t verify on a page. Any time behaviors change, they rerun the AI agents to relearn how the app works. Autonomous testing will revolutionize functional software testing by lowering the cost of entry for automation.
Catching the Next Wave
If you are plugged into software testing communities, you’ll hear from multiple testing leaders about their thoughts on the direction of our discipline. You’ll learn about trends, tools, and frameworks. You’ll see new design patterns challenge old ones. Something I want you to think about in the back of your mind is this: How can these things be adapted to autonomous testing? Will these tools and practices complement autonomous testing, or will they be replaced? The wave is coming, and it’s coming soon. Be ready to catch it when it crests.





{kind=link}
{kind=link}