Parallel testing is a powerful tool you can use to speed up your Applitools tests, but ensuring test batches are grouped together and not split is a common issue. Here’s how to avoid it.
Visual testing with Applitools Eyes is an awesome way to supercharge your automated tests with visual checkpoints that catch more problems than traditional assertions. However, just like with any other kind of UI testing, test execution can be slow. The best way to shorten the total start-to-finish time for any automated test is parallelization. Applitools Ultrafast Grid performs ultrafast visual checkpoints concurrently in the cloud, but the functional tests that initially capture those snapshots can also be optimized with parallel execution. Frameworks like JUnit, SpecFlow, pytest, and Mocha all support parallel testing.
If you parallelize your automated test suite in addition to your visual snapshot analysis, then you might need to inject a custom batch ID to group all test results together. What? What’s a batch, and why does it need a special ID? I hit this problem recently while automating visual tests with Playwright. Let me show you the problem with batches for parallel tests, and then I’ll show you the right way to handle it.
Parallel Playwright Tests
If you haven’t already heard, Playwright is a relatively new web testing framework from Microsoft. I love it because it solves many of the problems with browser automation, like setup, waiting, and network control. Playwright also has implementations in JavaScript/TypeScript, Python, Java, and C#.
Typically, I program Playwright in Python, but today, I tried TypeScript. I wrote a small automated test suite to test the AppliFashion demo web app. You can find my code on GitHub here: https://github.com/AutomationPanda/applitools-holiday-hackathon-2020.
The file tests/hooks.ts contains the Applitools setup:
import { test } from '@playwright/test';
import { Eyes, VisualGridRunner, Configuration, BatchInfo, BrowserType, DeviceName } from '@applitools/eyes-playwright';
export let Runner: VisualGridRunner;
export let Batch: BatchInfo;
export let Config: Configuration;
test.beforeAll(async () => {
Runner = new VisualGridRunner({ testConcurrency: 5 });
Batch = new BatchInfo({name: 'AppliFashion Tests'});
Config = new Configuration();
Config.setBatch(Batch);
Config.addBrowser(1200, 800, BrowserType.CHROME);
Config.addBrowser(1200, 800, BrowserType.FIREFOX);
Config.addBrowser(1200, 800, BrowserType.EDGE_CHROMIUM);
Config.addBrowser(1200, 800, BrowserType.SAFARI);
Config.addDeviceEmulation(DeviceName.iPhone_X);
});
Before all tests start, it sets up a batch named “AppliFashion Tests” to run the tests against five different browser configurations in the Ultrafast Grid. This is a one-time setup.
Among other pieces, this file also contains a function to build the Applitools Eyes object using Runner and Config:
export function buildEyes() {
return new Eyes(Runner, Config);
}
The file tests/applifashion.spec.ts contains three tests, each with visual checks:
import { test } from '@playwright/test';
import { Eyes, Target } from '@applitools/eyes-playwright';
import { buildEyes, getAppliFashionUrl } from './hooks';
test.describe('AppliFashion', () => {
let eyes: Eyes;
let url: string;
test.beforeAll(async () => {
url = getAppliFashionUrl();
});
test.beforeEach(async ({ page }) => {
eyes = buildEyes();
await page.setViewportSize({width: 1600, height: 1200});
await page.goto(url);
});
test('should load the main page', async ({ page }) => {
await eyes.open(page, 'AppliFashion', '1. Main Page');
await eyes.check('Main page', Target.window().fully());
await eyes.close(false);
});
test('should filter by color', async ({ page }) => {
await eyes.open(page, 'AppliFashion', '2. Filtering');
await page.locator('id=SPAN__checkmark__107').click();
await page.locator('id=filterBtn').click();
await eyes.checkRegionBy('#product_grid', 'Filter by color')
await eyes.close(false);
});
test('should show product details', async ({ page }) => {
await eyes.open(page, 'AppliFashion', '3. Product Page');
await page.locator('text="Appli Air x Night"').click();
await page.locator('id=shoe_img').waitFor();
await eyes.check('Product details', Target.window().fully());
await eyes.close(false);
});
test.afterEach(async () => {
await eyes.abort();
});
});
By default, Playwright would run these three tests using one “worker,” meaning they would be run serially. We can run them in parallel by adding the following setting to playwright.config.ts:
import type { PlaywrightTestConfig } from '@playwright/test';
import { devices } from '@playwright/test';
const config: PlaywrightTestConfig = {
//...
fullyParallel: true,
//...
};
export default config;
Now, Playwright will use one worker per processor or core on the machine running tests (unless you explicitly set the number of workers otherwise).
Split Batches
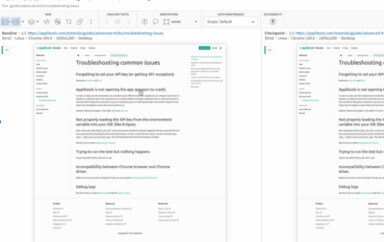
We can run these tests using the command npm test. (Available scripts can be found under package.json.) On my machine, they ran (and passed) with three workers. When we look at the visual checkpoints in the Applitools dashboard, we’d expect to see all results in one batch. However, we see this instead:
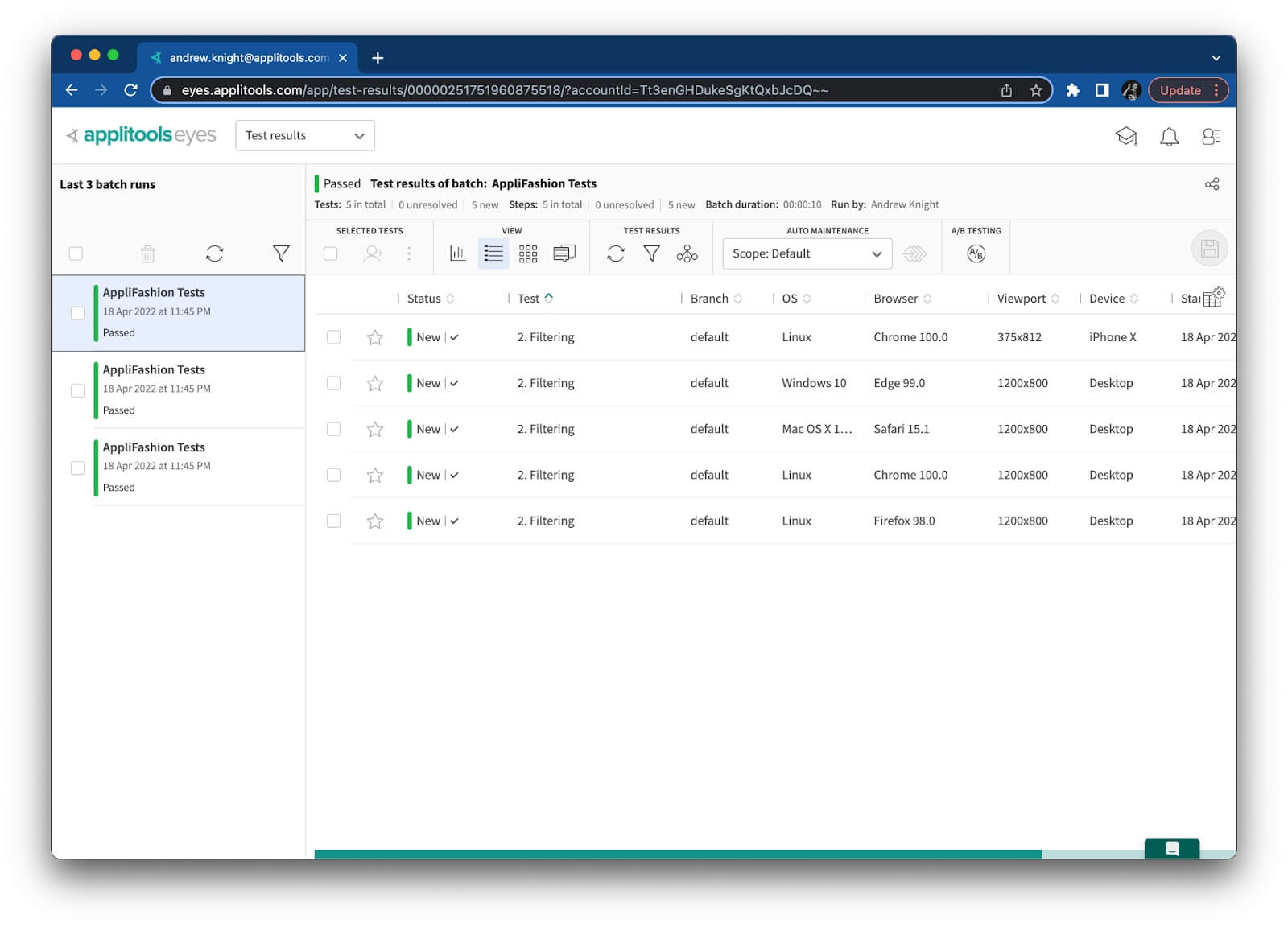
What in the world? There are three batches, one for each worker! All the results are there, but split batches will make it difficult to find all results, especially for large test suites. Imagine if this project had 300 or 3000 tests instead of only 3.
The docs on how Playwright Test handles parallel testing make it clear why the batch is split into three parts:
Note that parallel tests are executed in separate worker processes and cannot share any state or global variables.
Each test executes all relevant hooks just for itself, including beforeAll and afterAll.
So, each worker process essentially has its own “copy” of the automation objects. The BatchInfo object is not shared between these tests, which causes there to be three separate batches.
Unfortunately, batch splits are a common problem for parallel testing. I hit this problem with Playwright, but I’m sure it happens with other test frameworks, too.
Sharing a Unique Batch ID
Thankfully, there’s an easy way to fix this problem: share a unique batch ID between all concurrent tests. Every batch has an ID. According to the docs, there are three ways to set this ID:
- Explicitly set it on a
BatchInfoobject. - Set it using the
APPLITOOLS_BATCH_IDenvironment variable. - Don’t specify it, and let the system automatically generate a random ID.
My original code fell to option 3: I didn’t specify a batch ID, so each worker created its own BatchInfo object with its own automatically generated ID. That’s why my test results were split into three batches.
Option 1 is the easiest solution. We could hardcode a batch ID like this:
Batch = new BatchInfo({name: 'AppliFashion Tests', id: 'applifashion'});However, hardcoding IDs is not a good solution. This ID would be used for every batch this test suite ever runs. Applitools has features to automatically close batches, but if separate batches run too close together, then they could collide on this common ID and be reported as one batch. Ideally, each batch should have a unique ID. Unfortunately, we cannot generate a unique ID within Playwright code because objects cannot be shared across workers.
Therefore, option 2 is the best solution. Wecould set the APPLITOOLS_BATCH_ID environment variable to a unique ID before each test run. For example, on macOS or Linux, we could use the uuidgen command to generate UUIDs like this:
APPLITOOLS_BATCH_ID=$(uuidgen) npm testThe ID doesn’t need to be a UUID. It could be any string, like a timestamp. However, UUIDs are recommended because the chances of generating duplicate IDs is near-zero. Timestamps are more likely to have collisions. (If you’re on Windows, then you’ll need to come up with a different command for generating unique IDs than the one shown above.)
Now, when I run my test with this injected batch ID, all visual test results fall under one big batch:
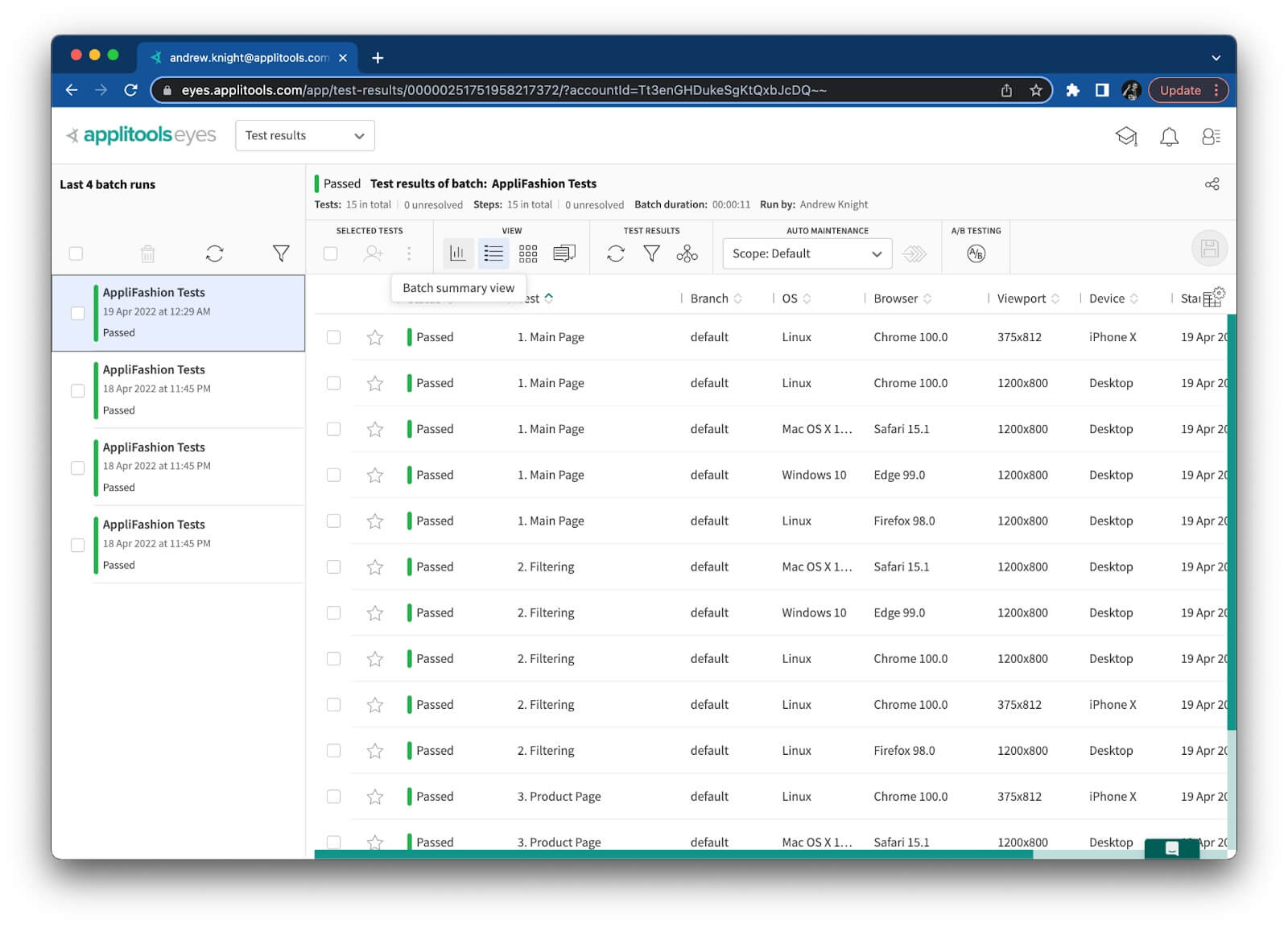
That’s the way it should be! Much better.
Conclusion
I always recommend setting a concise, informative batch name for your visual tests. Setting a batch ID, however, is something you should do only when necessary – such as when tests run concurrently. If you run your tests in parallel and you see split batches, give the APPLITOOLS_BATCH_ID environment variable a try!