Test Categories
When it comes to Test Strategy for any reasonable sized / complex product, one aspect would always be there – the categories of tests that would be created, and (hopefully) automated – ex: Smoke, Sanity, Regression, etc.
Have you ever wondered why these categories are required? Well, the answer is quite simple. We want to get quick feedback from our tests (re-executed by humans, or better yet – by machines in the form of automated tests). These categories offer a stepping-stone approach to getting feedback quickly.
But, have you wondered, why is your test feedback slow for functional automation? In most cases, the number of unit tests would be a decent multiple (10-1000x) of the number of automated functional tests. YET, I have never ever seen categories like smoke, sanity, regression being created for the unit tests. Why? Again, the answer is very simple – the unit tests run extremely fast and provide feedback almost immediately.
The next question is obvious – why are the automated tests slow in giving running and providing feedback? There could be various reasons for this:
- The functional tests have to launch the browser / native application before running the test
- The test runs against fully / partially integrated system (as opposed to to a stubbed / mocked unit test)
However, there are also other factors that contribute to the slow functional tests:
- Non-optimal tool sets used for automation
- Skills / capabilities on the team do not match what is required to automate effectively
- Test automation strategy / criteria is not well defined.
- The Test Automation framework is not designed & architected correctly, hence making it inefficient, slow, and gives inconsistent results.
- Repeating the execution of the same set of Functional Automated Tests on variety of browsers, and viewport sizes
Getting faster feedback from Automated Functional Tests
There are various techniques & practices that can be used (appropriately, and relevant to the context of product-under-test) to get faster, reliable, consistent feedback from your Functional Tests.
Some of these are:
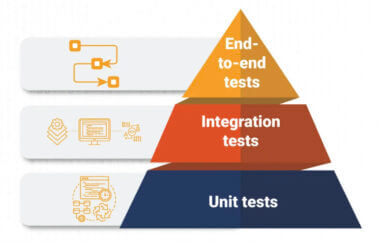
- Evolve your test strategy based on the concept of Test Automation Pyramid
- Design & architect your Functional Test Automation Framework correctly. This post on “Test Automation in the World of AI & ML” highlights various criteria to be considered to build a good Test Automation Framework.
- Include Visual AI solution from Applitools that speeds up test implementation, reduces flakiness in your Functional Automation execution, includes AI-based Visual Testing and eliminates the need for Cross-browser testing – i.e. removes the need to execute the same functional tests in multiple browsers
Optimizing Functional Tests using Visual AI
Let’s say I want to write tests to login to github.
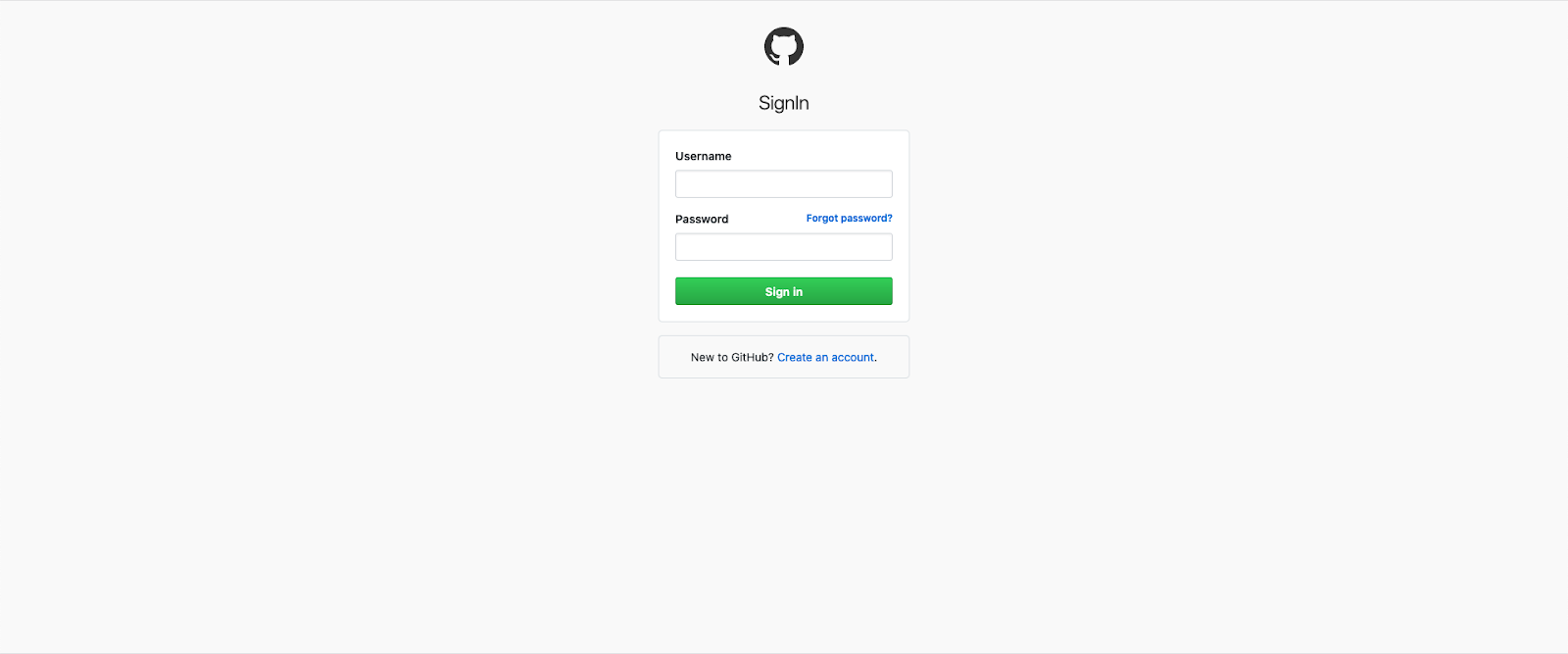
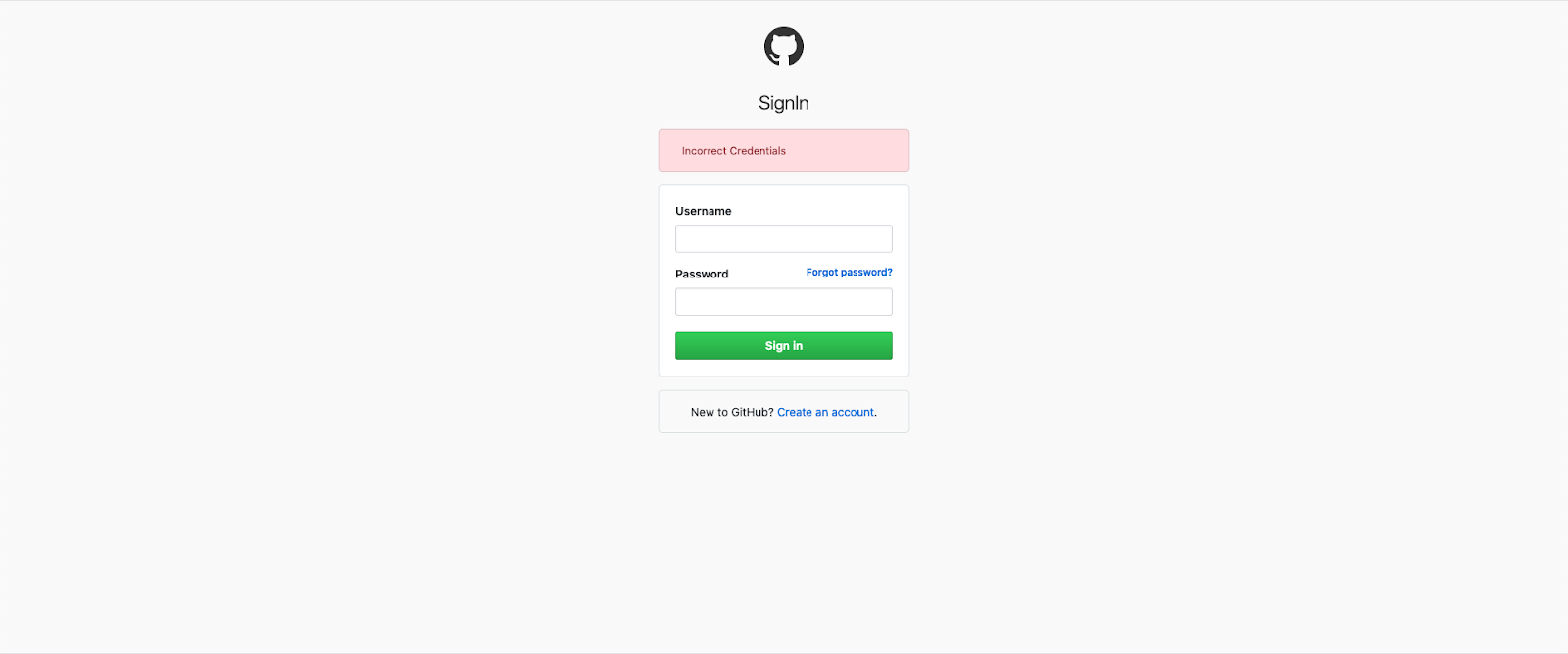
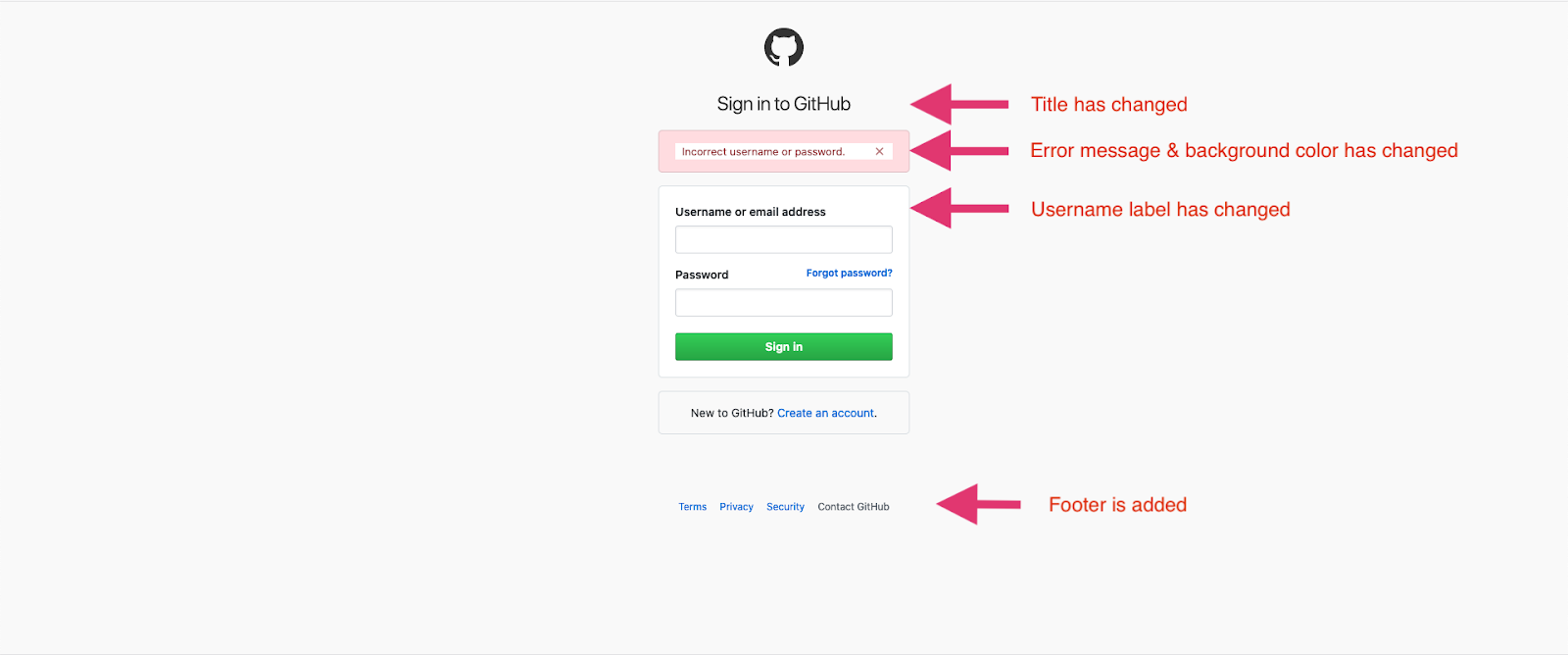
Expected functionality is that if I click on “Sign In” button without entering any credentials, I see the error message as below:
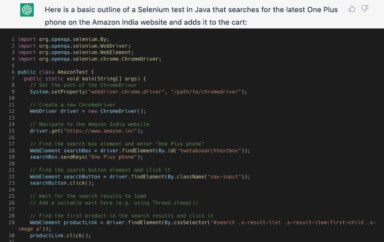
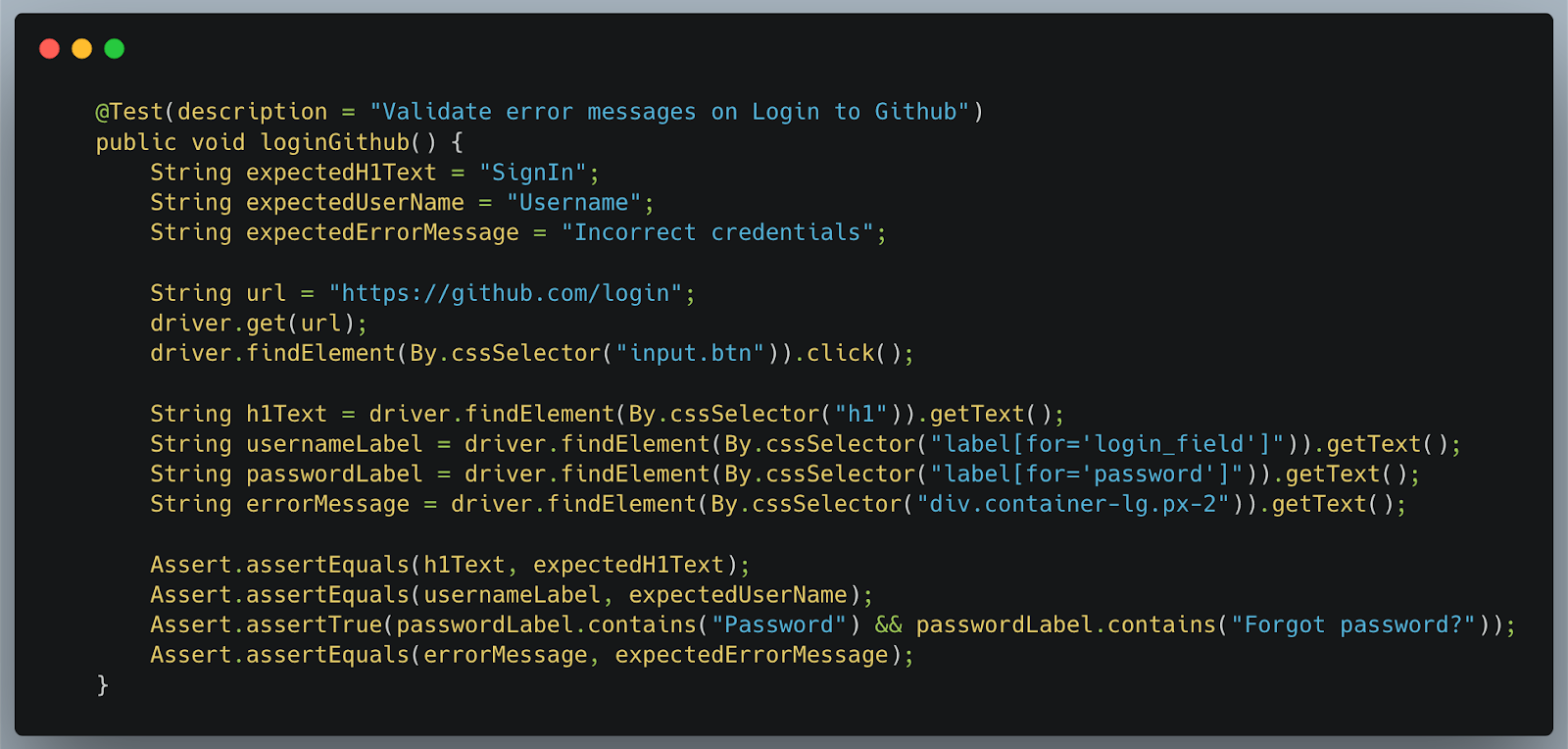
To implement a Selenium-based test for such validation, I would write it as below:
Now, when I run this test against a new build, which may have added functionality, like shown below, lets see the status of this test result.
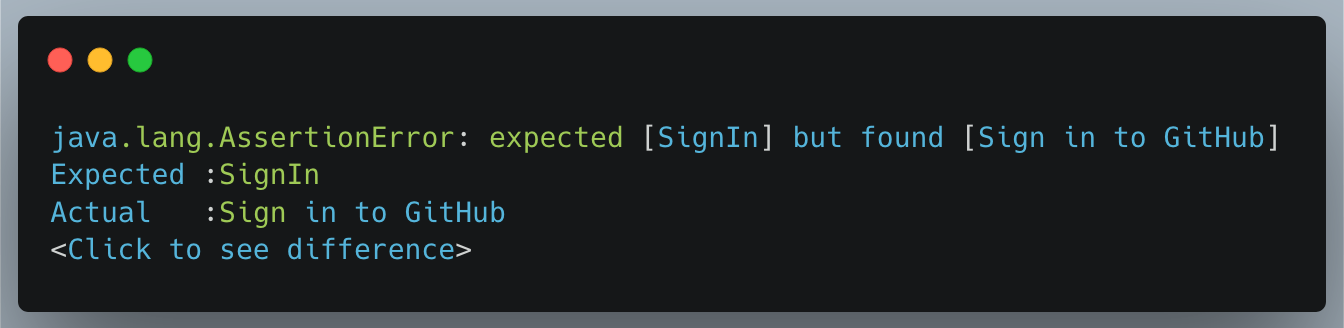
Sure enough, the test failed. If we investigate why, you will see that the functionality has evolved.
However, our implemented test failed for the 1st error it found, i.e.
The title of the page has changed from “SignIn” to “Sign in to Github”
I am sure you have also experienced these types of test results.
The challenges I see with the above are:
- The product-under-test is always going to evolve. That means your test is always going to report incorrect details
- In this case, the test reported only the 1st failure it came across, i.e. the 1st assertion failure. The rest of the issues that could have been captured by the test were not even executed.
- The test would not have been to capture the color changes
- The new functionality did not have any relevance to the automated test
Is there a better way to do this?
YES – there is! Use Applitools Visual AI!
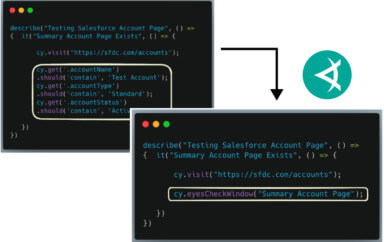
After signing up for a free Applitools account, I integrated Applitools Selenium-Java SDK using the tutorial into my test.
My test now looks like this:
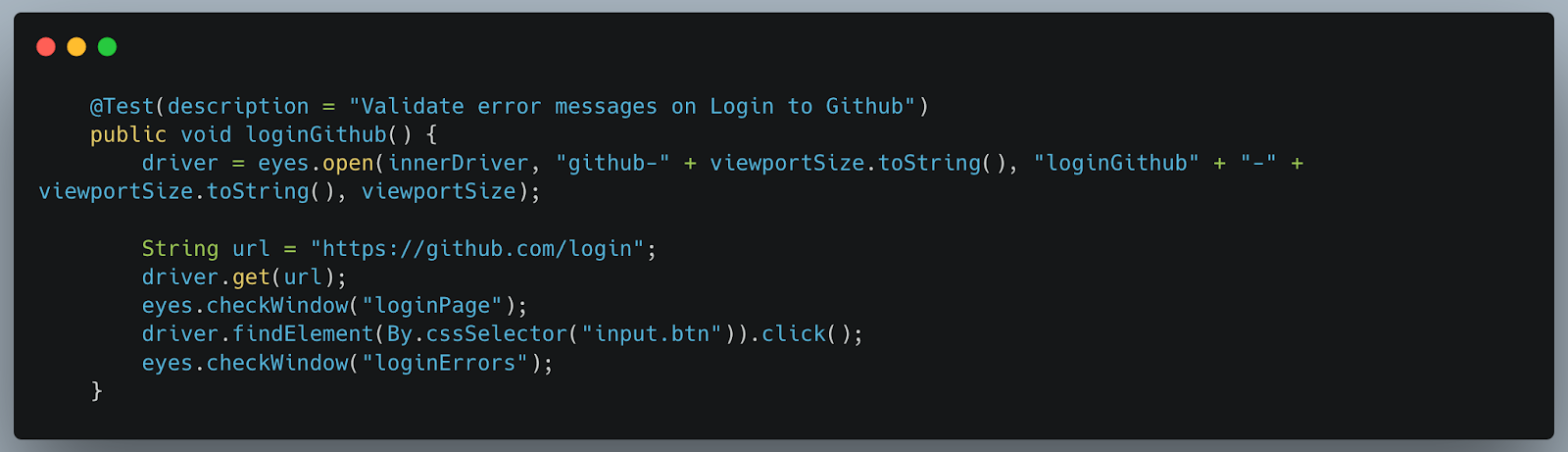
As you can see, my test code has the following changes:
- There are no assertions that I had before
- There are hence, fewer locators I need to worry about
- Hence the test code is more stable, faster, cleaner & simpler
The test still fails in this case as well, because of the new build. However, the reason for the failures is very interesting.
When I look at the Applitools dashboard for these mismatches reported, I am able to see the details of what went wrong, functionally & visually!
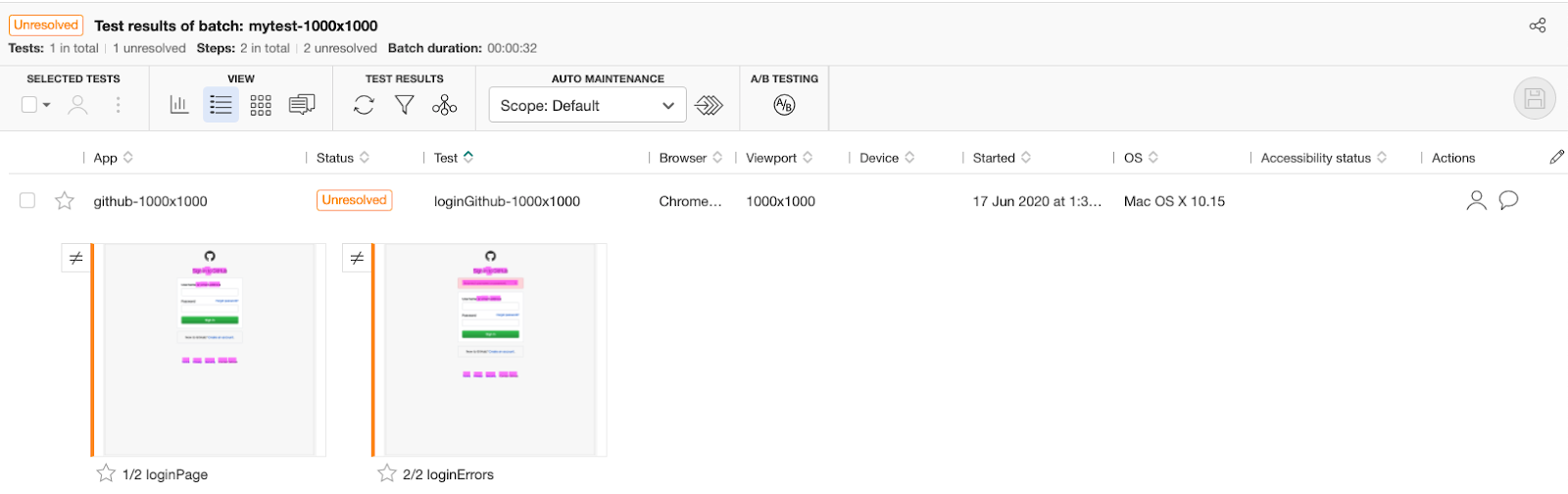
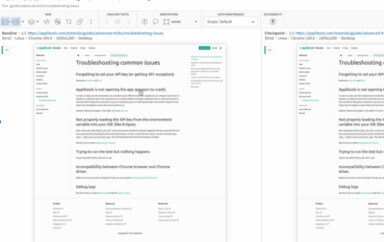
Here are the details of the errors
Screen 1 – before login
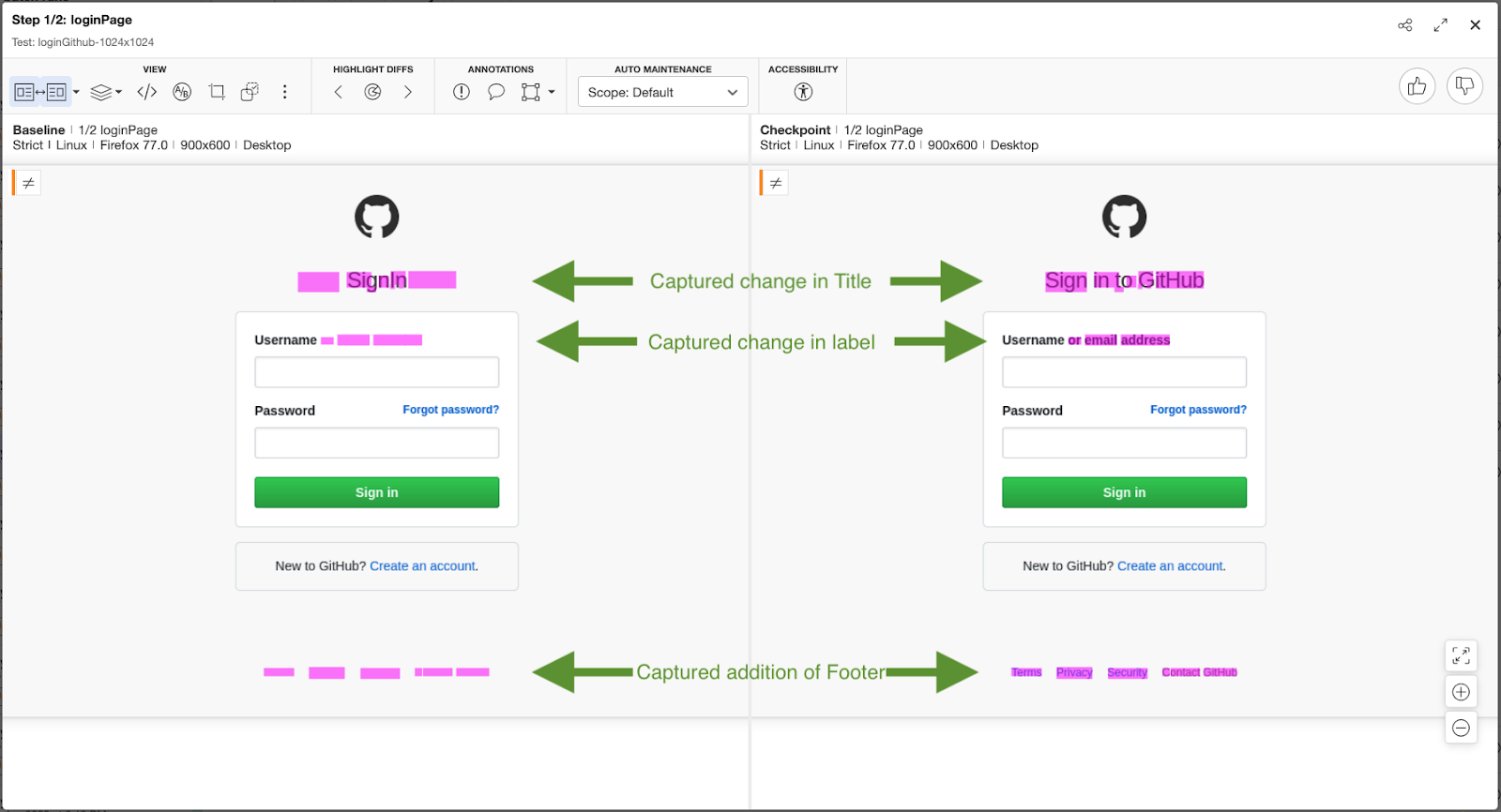
Screen 2 – after login with no credentials provided
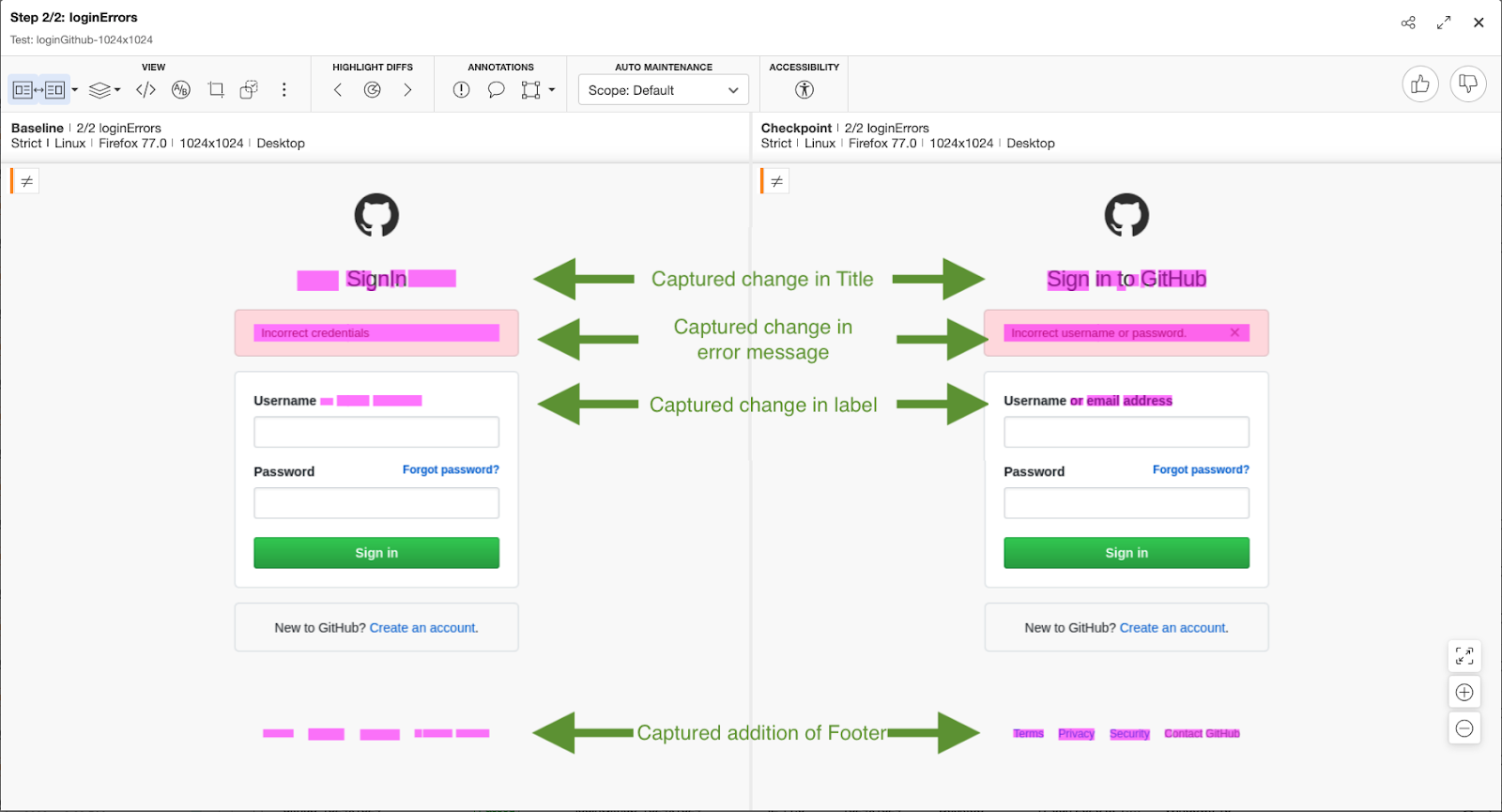
From this point, now, I can report the failures in functionality / user experience as a defect using the Jira integration, and accept the new functionality and update the baseline appropriately, with simple clicks in the dashboard.
Scaling the test execution
A typical way to scale the test is to set up your own infrastructure with different browser versions, or to use a cloud provider which will manage the infrastructure & browsers. There are a lot of disadvantages in either approach – from a cost, maintenance, security & compliance perspective.
To use any of the above solutions, you first need to ensure that your tests can run successfully and deterministically against all the supported browsers. That is a substantial added effort.
This approach of scaling seems flawed to me.
If you think about it, where are the actual bugs coming from? In my opinion, the bugs are related to:
- Server bugs which are device / browser independent
Ex: A broken DB query, logical error, backend performance issues, etc.
- Functional bugs – which are 99% are device / browser agnostic. This is because:
- Modern browsers conform to the W3C standard
- Logical bugs occur in all client environments.
Examples: not validating an input field, reversed sorting order, etc.
That said, though the browsers are W3C standard compliant, they still have their own implementation of the rendering engines, which means, the real value of running tests in different browsers and varying viewport sizes is in finding visual bugs!
By using Applitools, I get access to another awesome feature, due to which I can avoid running the same set of tests on multiple browsers & viewport sizes. This ended up saving my test implementation, execution and maintenance time. That is the Applitools Ultrafast Grid.
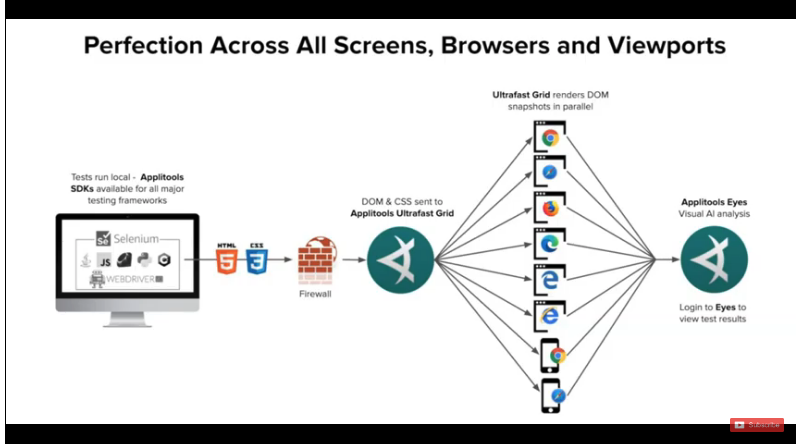
See this quick video from about the Applitools Ultrafast Grid.
To enable the Applitools Ultrafast Grid, I just needed to add a few configuration details when instantiating Eyes. In my case, I added the below to my Eyes configuration.
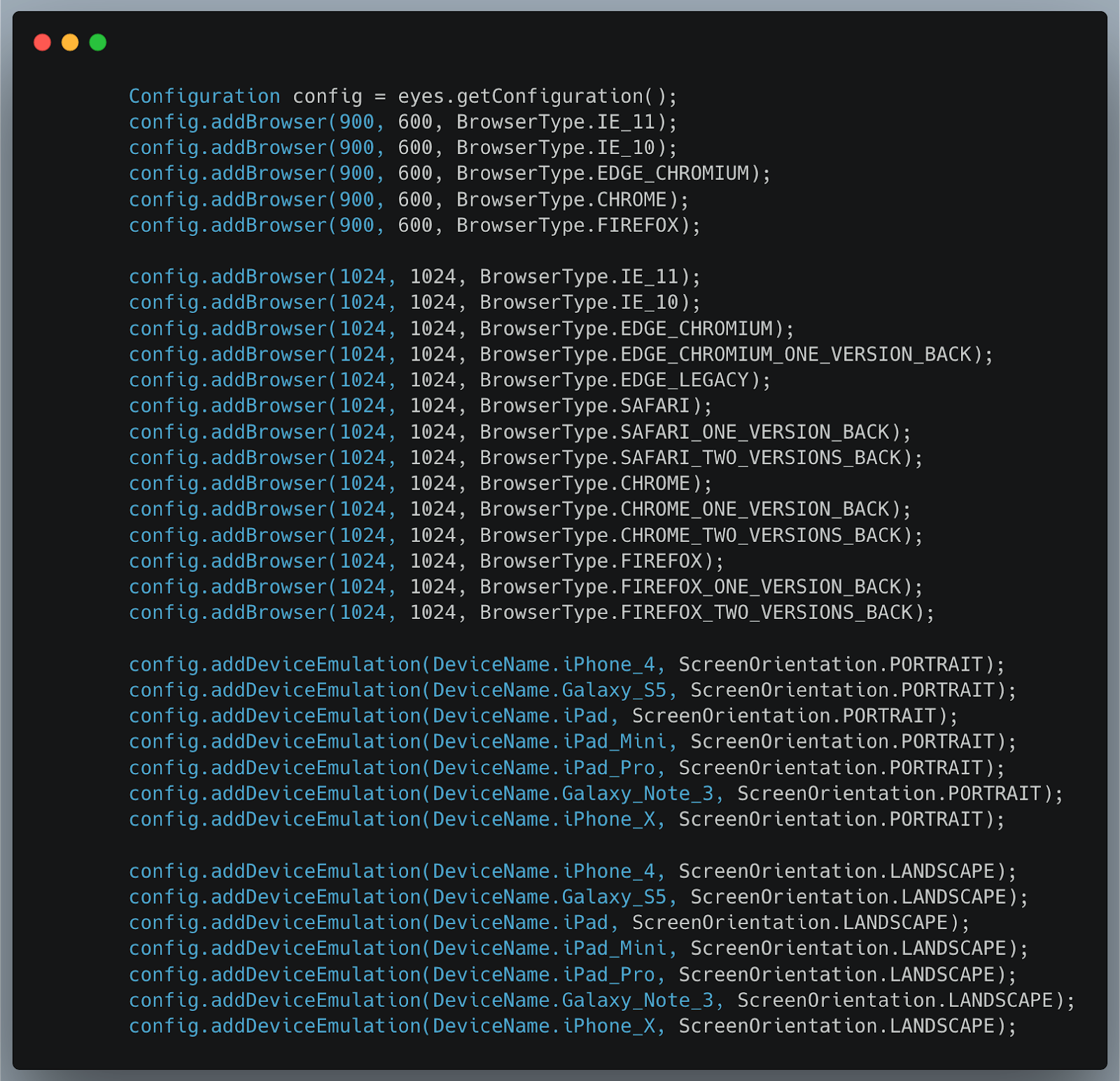
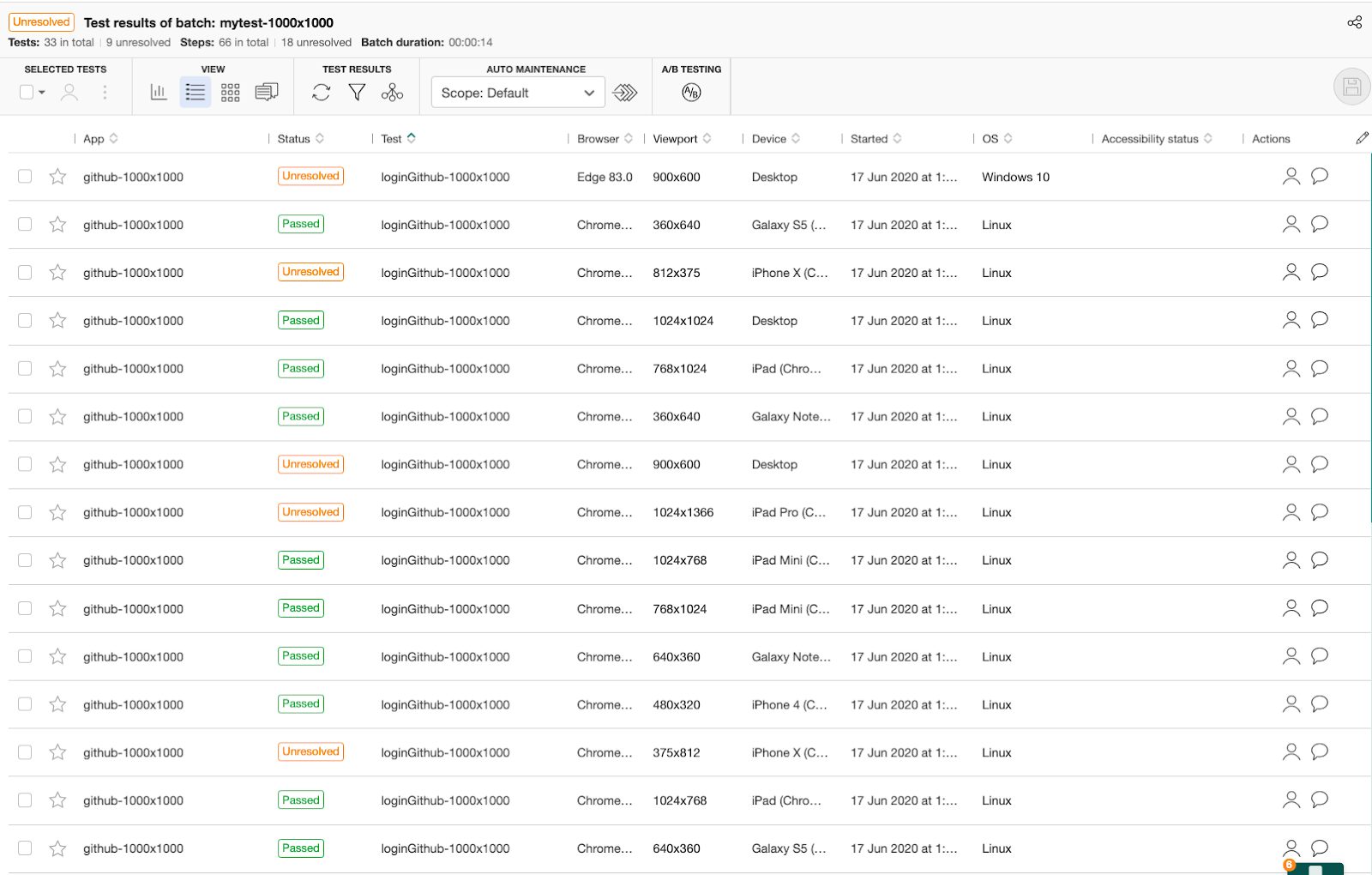
When I ran my test again on my laptop, and checked the results in the Applitools dashboard, I saw the awesome power of the Ultrafast Grid.
NOTE: The test ran just once on my laptop, however the Ultrafast Grid rendered the same screenshots by capturing the relevant page’s DOM & CSS in each of the browser & viewport combinations I provided above, and then did a visual comparison. As a result, in a little more than regular test execution time, I got functional & visual validation done for ALL my supported / provided configurations. Isn’t that neat!
Do we need Smoke, Sanity, Regression suites?
To summarize:
- Do not blindly start with classifying your tests in different categories. Challenge yourself to do better!
- Have a Test Automation strategy and know your test automation framework objective & criteria (“Test Automation in the World of AI & ML” highlights various criteria to be considered to build a good Test Automation Framework)
- Choose the toolset wisely
- After all the correct (subjective) approaches taken, if your test execution (in a single browser) is still taking more than say, 10 min for execution, then you can run your tests in parallel, and subsequently, split the test suite into smaller suites which can give you progressive indication of quality
- Applitools with its AI-power algorithms can make your functional tests lean, simple, robust and includes UI / UX validation
- Applitools Ultrafast Grid will remove the need for Cross-Browser testing, and instead with a single test execution run, validate functionality & UI / Visual rendering for all supported Browsers & Viewports