Do you believe in learning from the experiences of others? If others found themselves more productive adding Visual AI to their functional tests, would you give it a try?
In November 2019, over 3,000 engineers signed up to participate in the Applitools Visual AI Rockstar Hackathon. 288 completed the challenge and submitted tests – comparing their use of coded test validation versus the same tests using Visual AI. They found themselves with better coverage, faster test development, more stable test code, with easier code test code maintenance.
On April 23, James Lamberti, CMO at Applitools, and Raja Rao DV, Director of Growth Marketing at Applitools, discussed the findings from the Applitools Hackathon submissions. The 288 engineers who submitted their test code for evaluation by the Hackathon team spent an average of 11 hours per submission. That’s over 3,000 person-hours – the equivalent of 1 ½ years of engineering work.
Over 3000 participants signed up. They came from around the world.

They used a variety of testing tools and a range of programming languages.
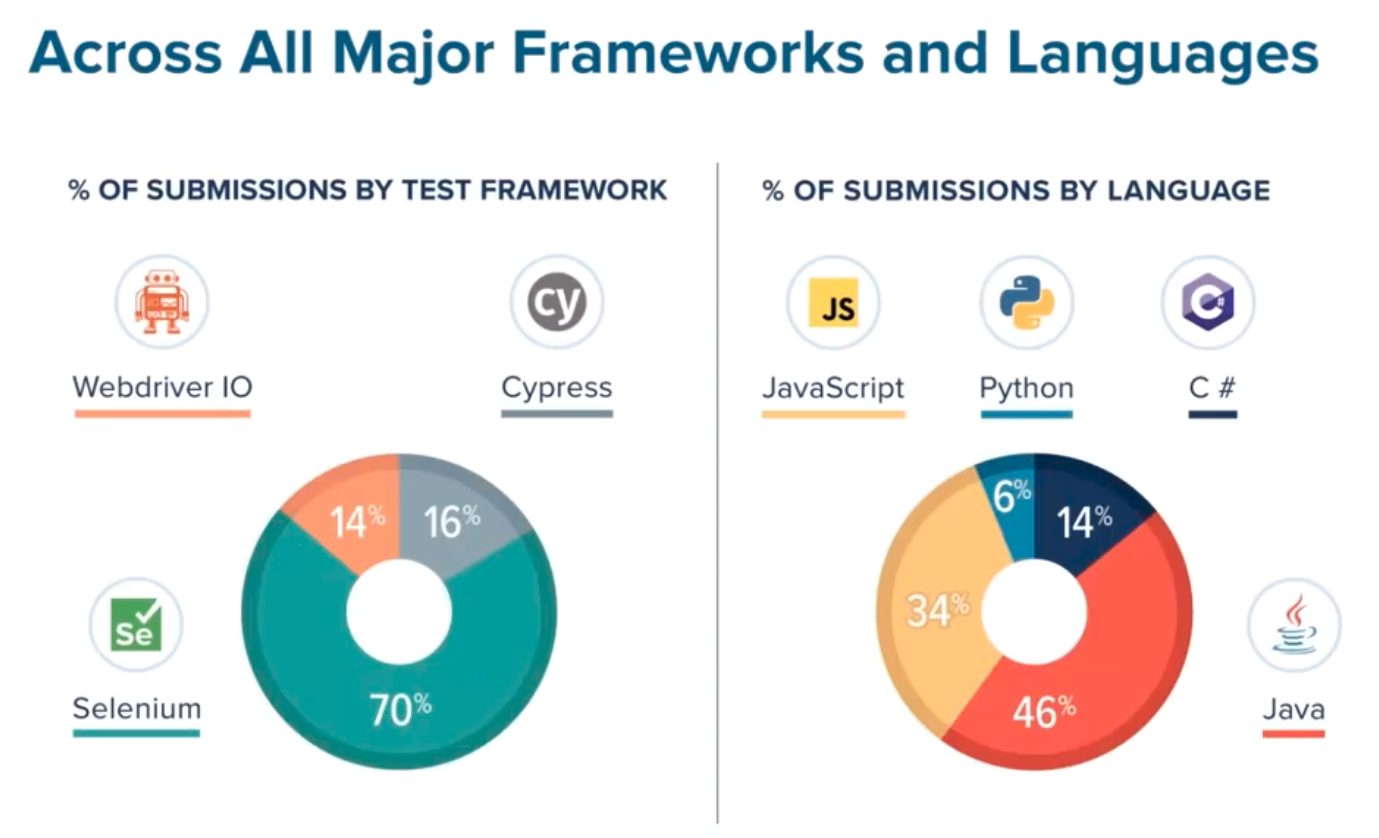
In the end, they showed some pretty amazing results from adding Applitools Visual AI to their existing test workflow.
Describing the Hackathon Tests
Raja described the tests that made up the Hackathon.
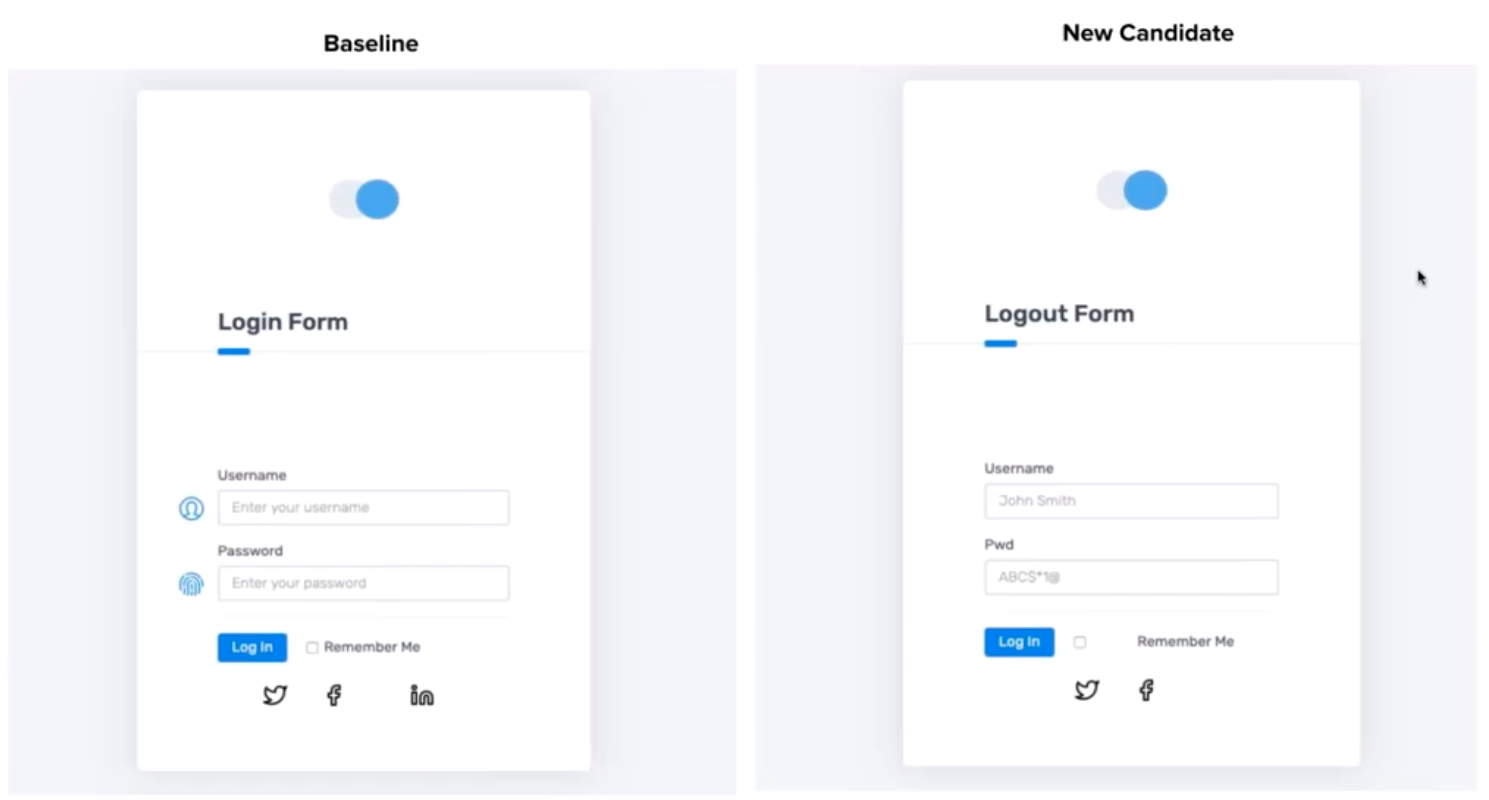
Each test involved a side-by-side comparison of two versions of a web app. In one version, the baseline, the page rendered correctly. In the other version, the new candidate, the page rendered with errors. This would simulate the real-world issues of dealing with test maintenance as apps develop new functionality.
Hackathon participants had to write code that did the following:
- Ensure the page rendered as expected on the baseline.
- Capture all mistakes in the page rendering on the new candidate
- Report on all the differences between the baseline and the new candidate
Also, Hackathon participants needed to realize that finding a single error on a page met the necessary – but not sufficient condition for testing. A single test that captures all the problems at once has a faster resolution time than running into multiple bug capture/fix loops. Test engineers needed to write tests that captured all the test conditions, as well as properly reporting all the failures.
Hackathon participants would code their test using a conventional test runner plus assertions of results in the output DOM. Then, they used the same test runner code but replaced all their assertions with Applitools Visual AI comparisons.
To show these test results, he used the Github repository of Corina Zaharia, one of the platinum Hackathon winners.
At this point here, Raja walked through each of the test cases.
CASE 1 – Missing Elements
Raja presented two web pages. One was complete. The other had missing elements. Hackathon participants had to find those elements and report them in a single test.
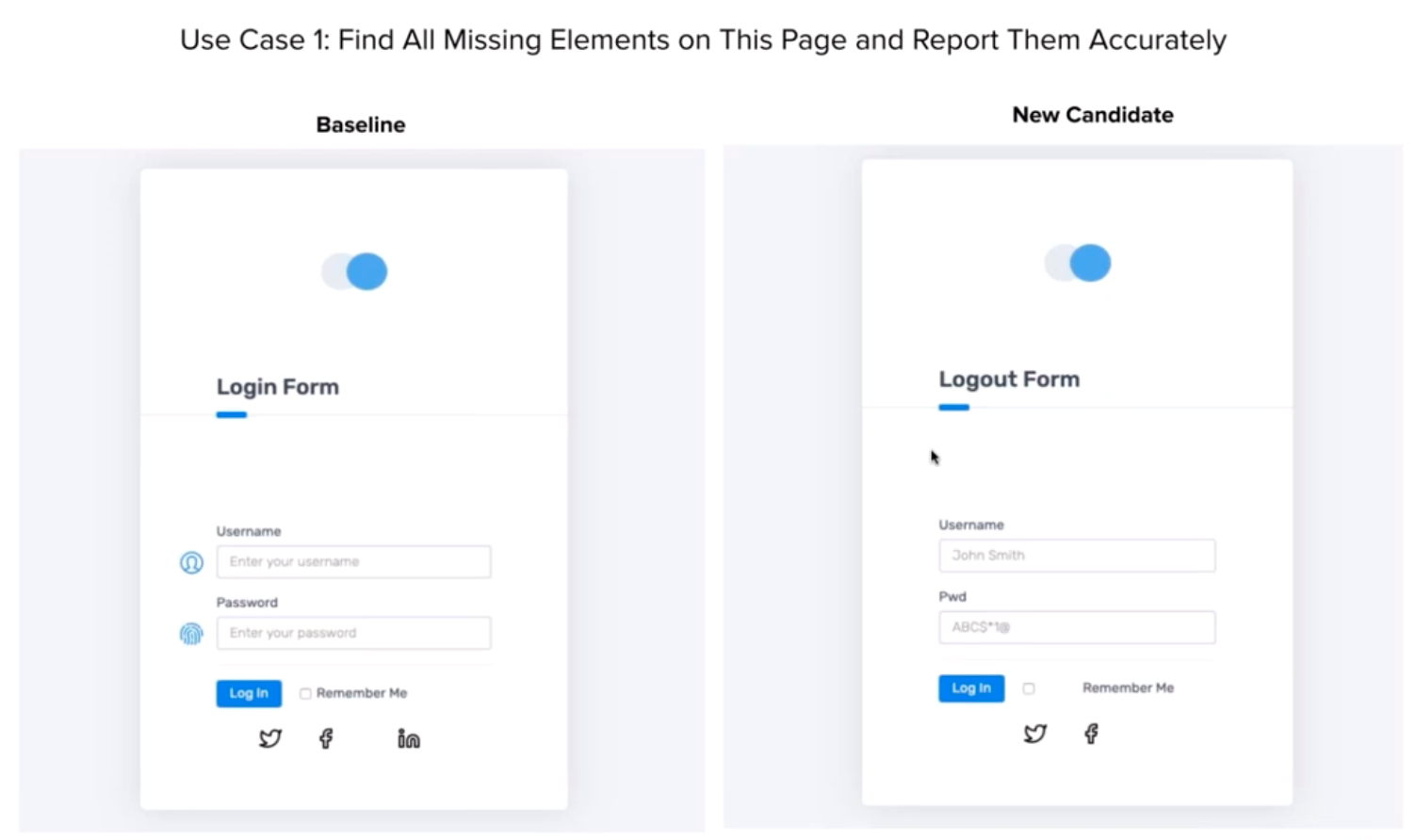
To begin coding tests, Corina started with the baseline. She identified each of the HTML elements and ensured that their text identifiers existed. She wrote assertions for every element on the page.
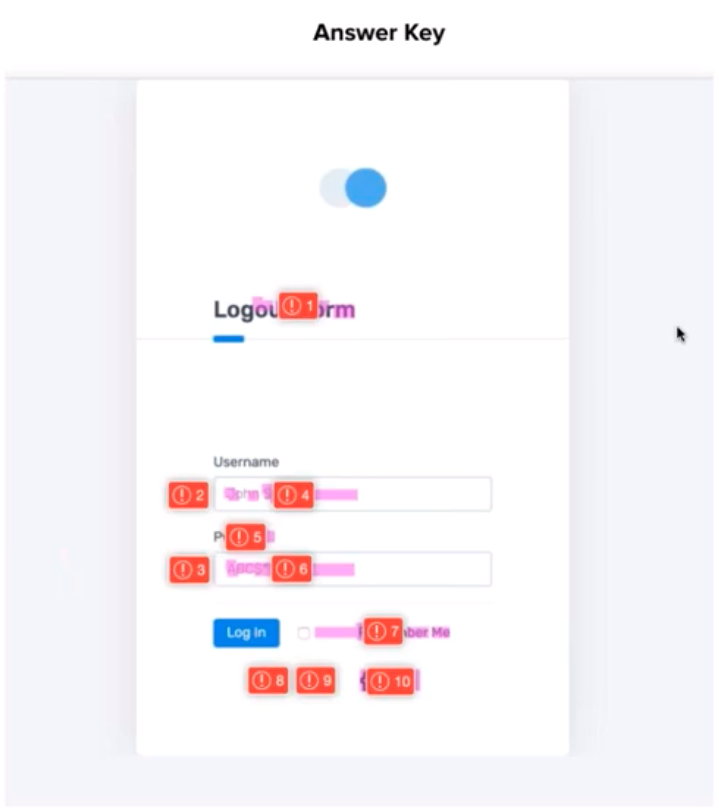
In evaluating submissions, judges ensured that the following differences got captured:
- The title changed
- The Username icon was missing
- The Password icon was missing
- The username placeholder changed
- The wrong password label
- The password placeholder changed
- There was extra space next to the check box
- The Twitter icon had moved
- The Facebook icon had moved
- The LinkedIn Icon was missing.
Capturing this page required identifying element locators and validating locator values.
In comparison, adding Visual AI required only three instructions:
- Open a capture session
- Capture the page with an eyes.checkWindow() command
- Close the capture session
No identifiers needed – Applitools captured the visual differences.
With much less coding, Applitools captured all the visual differences. And, test maintenance takes place in Applitools.
CASE 2 – Data-Driven Testing
In Case 2, Hackathon participants needed to validate how a login page behaved when applying different inputs. The test table looked like this:
- No username, no password
- Username, no password
- Password, no username
- Username and password combination invalid
- Valid username and password
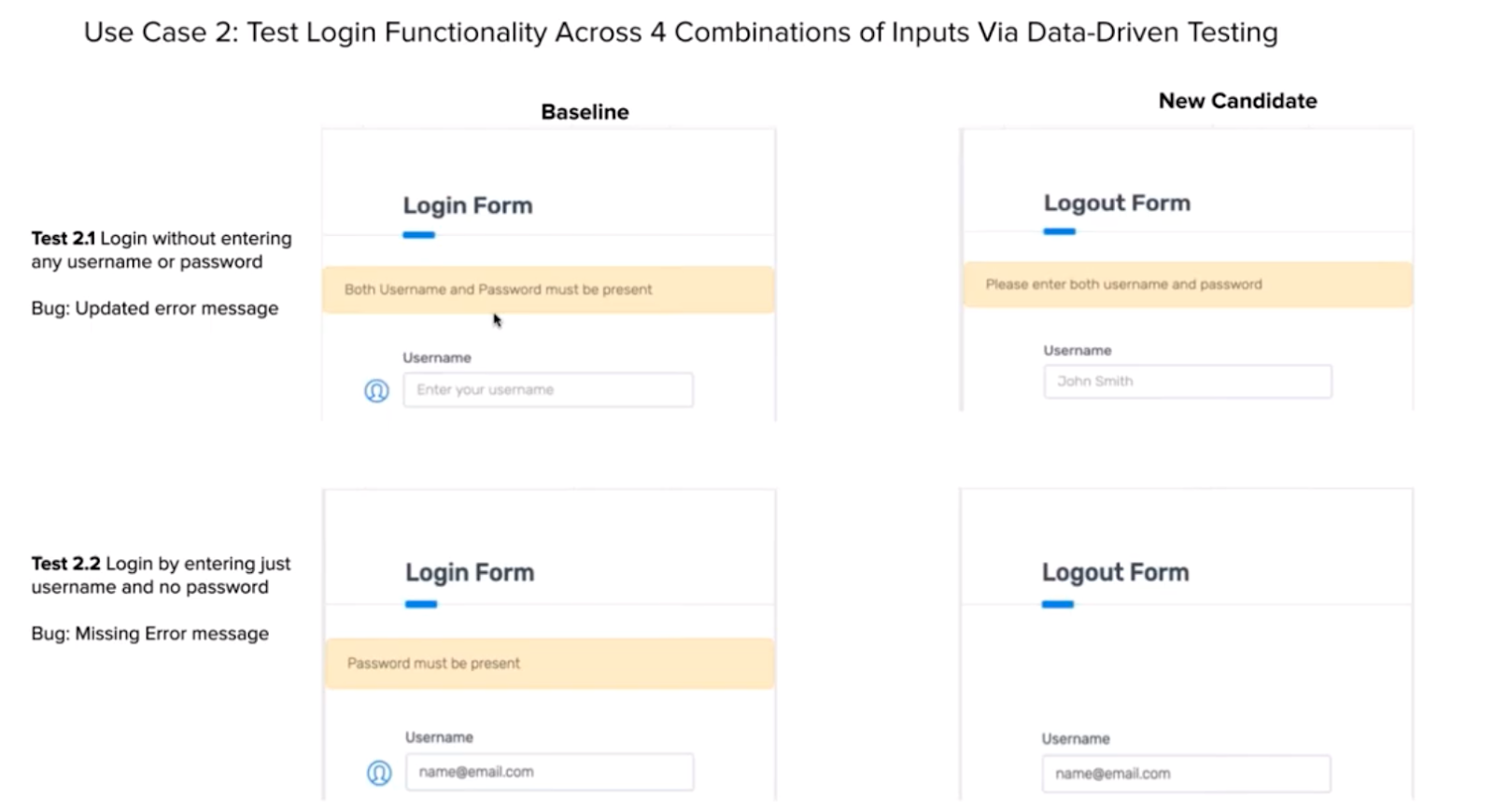
Each condition resulted in a different response page.
Hackathon participants found an identical page to the tests in Case 1 – but they were responsible for handling the different responses to each of the different test conditions.
Again, the coding for the conventional test required entering the test conditions via test runner asserting all the elements on the page, including asserting error messages.
Also, the question was left open for testers – what should they test when they test the valid password and username condition? The simplest answer – just make sure the app visits the correct target post-login page. But, more advanced testers wanted to make sure that the target paged rendered as expected.
So, again, the comparison with coded assertions and adding Visual AI makes clear how much more easily Visual AI captures baselines and then compares the new candidate against the baselines.
CASE 3 – Testing Table Sort
The next case – testing table capabilities – fits into capabilities found on many web apps that provide multiple selections. Many consumer apps, such as retailers, reviewers, and banks, provide tables for their customers. Some business apps provide similar kinds of selectors – in retail, financial, and medical applications. In many use cases, users expect tables with advanced capabilities, such as sorting and filtering.
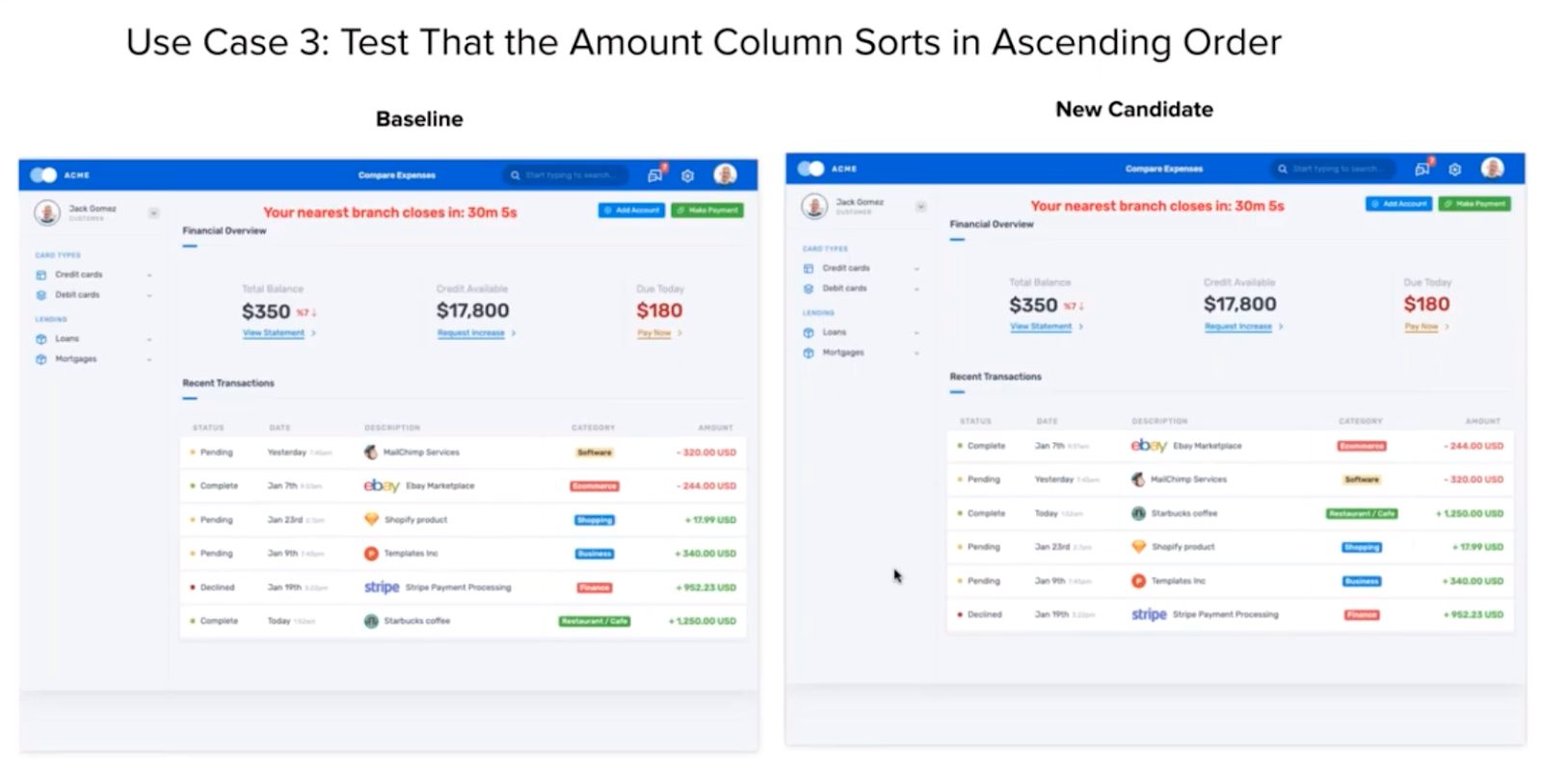
Tables can provide some challenges for testers. Tables can contain lots of elements. Many table functions can require complex test coding – for example, sorting and filtering.
To test table sorting with conventional assertion code, Hackathon participants had to write code that captured all the data in the table, performed the appropriate sort of that data, and use the internally-sorted table in the test code with the sorted table on the web page. Great test coders took pains to ensure that they had done this well and could handle various sorting options. The winners took time to ensure that their code covered the table behavior. This complex behavior did not get caught by all participants, even with a decent amount of effort.
In contrast, all the participants understood how to test the table sort with Visual AI. Capture the page, execute the sort, capture the result, and validate inside Applitools.
Case 4 – Non-Textual Plug-ins
The fourth case involved using graphical rendering of a table in canvas. How do you test that?
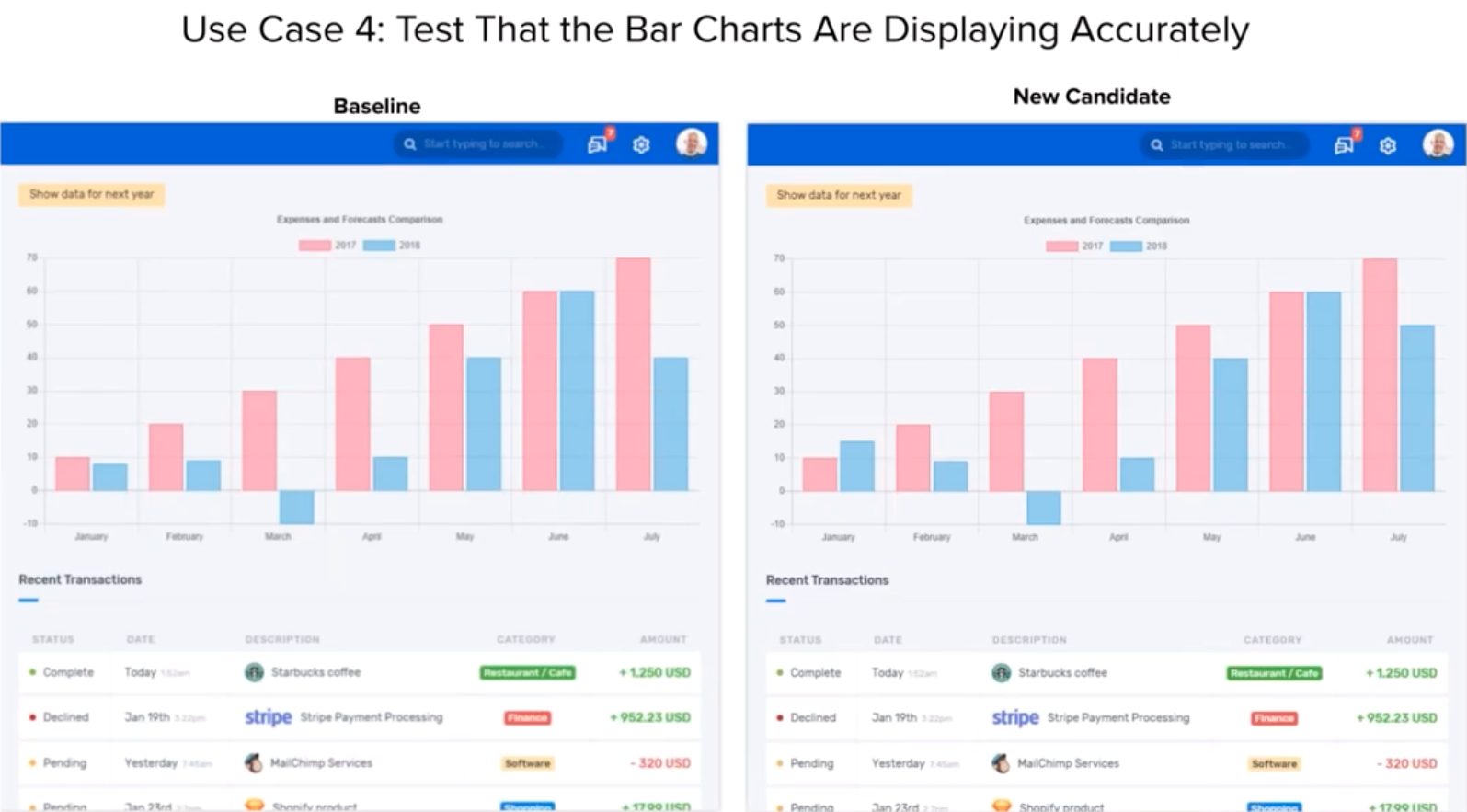
Without normal web element locators, a lot of participants got lost. They weren’t sure how to start finding the graphing elements and to build a comparison between the baseline behavior and the new candidate.
Winning Hackathon participants dug into the rendering code to find the javascript calls for the graph and the source data for table elements. This allowed them to extract the values that should be rendered and compare them between the baseline and the new candidate. And, while the winners wrote fairly elegant code, this particular skill took time to dive into JavaScript. And, a fair amount of coding effort.
As with the table sorting Case 3, all the participants understood how to test the graph with Visual AI. Capture the page, and then compare the new candidate with the baseline in Applitools.
Case 5 – Dynamic Data
The final case required the participants to test a page with floating advertisements that can change. In fact, as long as content gets rendered in the advertising box, and the rest of the candidate remains unchanged, the test passes.
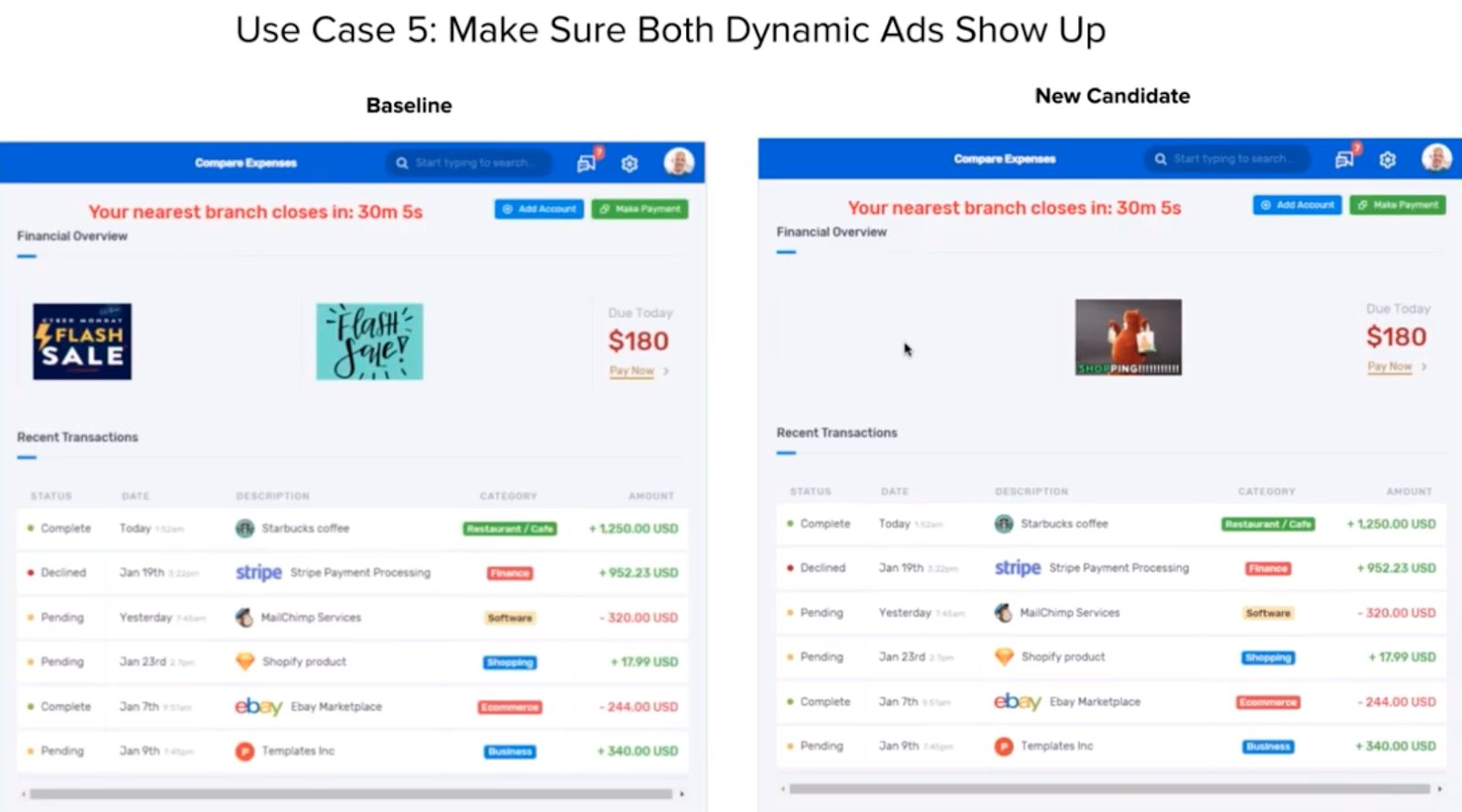
The winning participants coded conditional tests to ensure that code existed in the advertising boxes, though they did not have the ability to see how that code got rendered.
With Visual AI, participants had to use different visual comparison modes in Applitools. The standard mode – Strict Mode – searches for visual elements that have moved or rendered in unexpected ways. With dynamic data, Strict Mode comparisons fail.
For these situations, Applitools offers Layout Mode instead. When using Layout Mode, the text and graphical elements need to share order and orientation, but their actual visual representation can be different. In Layout Mode, the following are considered identical – image above text.

This Is A Dog

Not A Dog
However, the pair below has a different layout. On the left, the text sits below the image, while on the right the text sits above the image
This Is A Dog
Not A Dog
Applitools users can hard-code their check mode for different regions into their page capture. Alternatively, they can use Strict Mode for the entire page and handle the region as a Layout Mode exception in the Applitools UI.
All the Hackathon participants, whether coding their tests for Layout mode for the region or by using Layout mode for the selected area once the baseline had been captured in Applitools, had little difficulty coding their tests.
Learning From Hackathon Participants
At this point, James began describing what we had learned from the 1.5 person-years of coding work done on the Hackathon. We learned what gave people difficulty, where common problems occurred, and how testing with Visual AI compared with conventional assertions of values in the DOM.
Faster Test Creation
I alluded to it in the test description, but test authors wrote their tests much more quickly using Visual AI. On average, coders spent 7 person-hours writing coded assertion-based tests for the Hackathon test cases. In contrast, they spent a mere 1.2 hours writing tests using Visual AI for the same test cases.
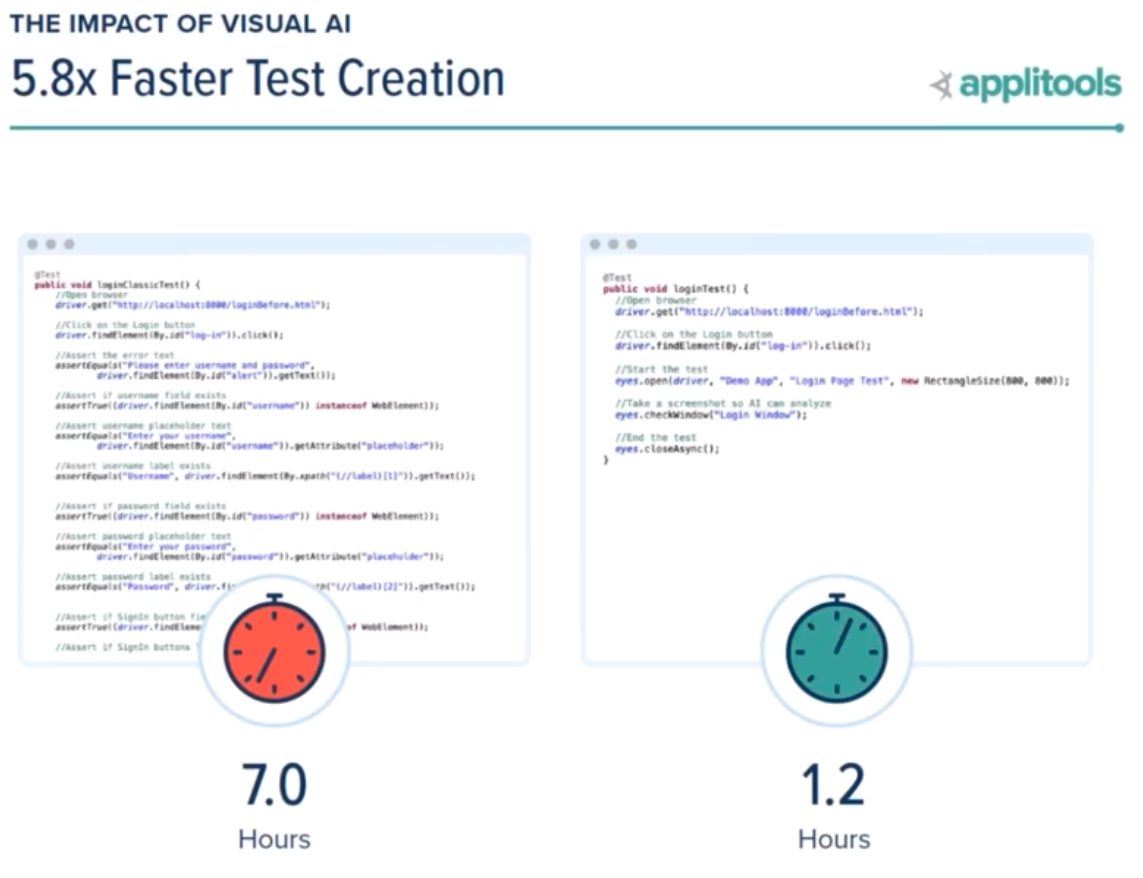
Interestingly, the prize-winning submitters spent, on average 10.2 hours writing their winning submissions. They wrote more thorough conventional tests, which would yield accurate coverage when failures did occur. On the other hand, their coverage did not match the complete-page coverage they got from Visual AI. And, their prize-winning Visual AI tests required, on average, six minutes more to write than the average of the whole of the test engineers.
More Efficient Coding
The next takeaway came from calculating coding efficiency. For conventional tests, the average participant wrote about 350 lines of code. The prize winners, whose code had greater coverage, wrote a little more than 450 lines of code, on average. This correlates with the 7 hours and 10 hours of time spent writing tests. It’s not a perfect measure, but participants writing conventional tests wrote about 50 lines of code per hour over 7 hours, and the top winners wrote about 45 lines of code per hour over 10 hours.
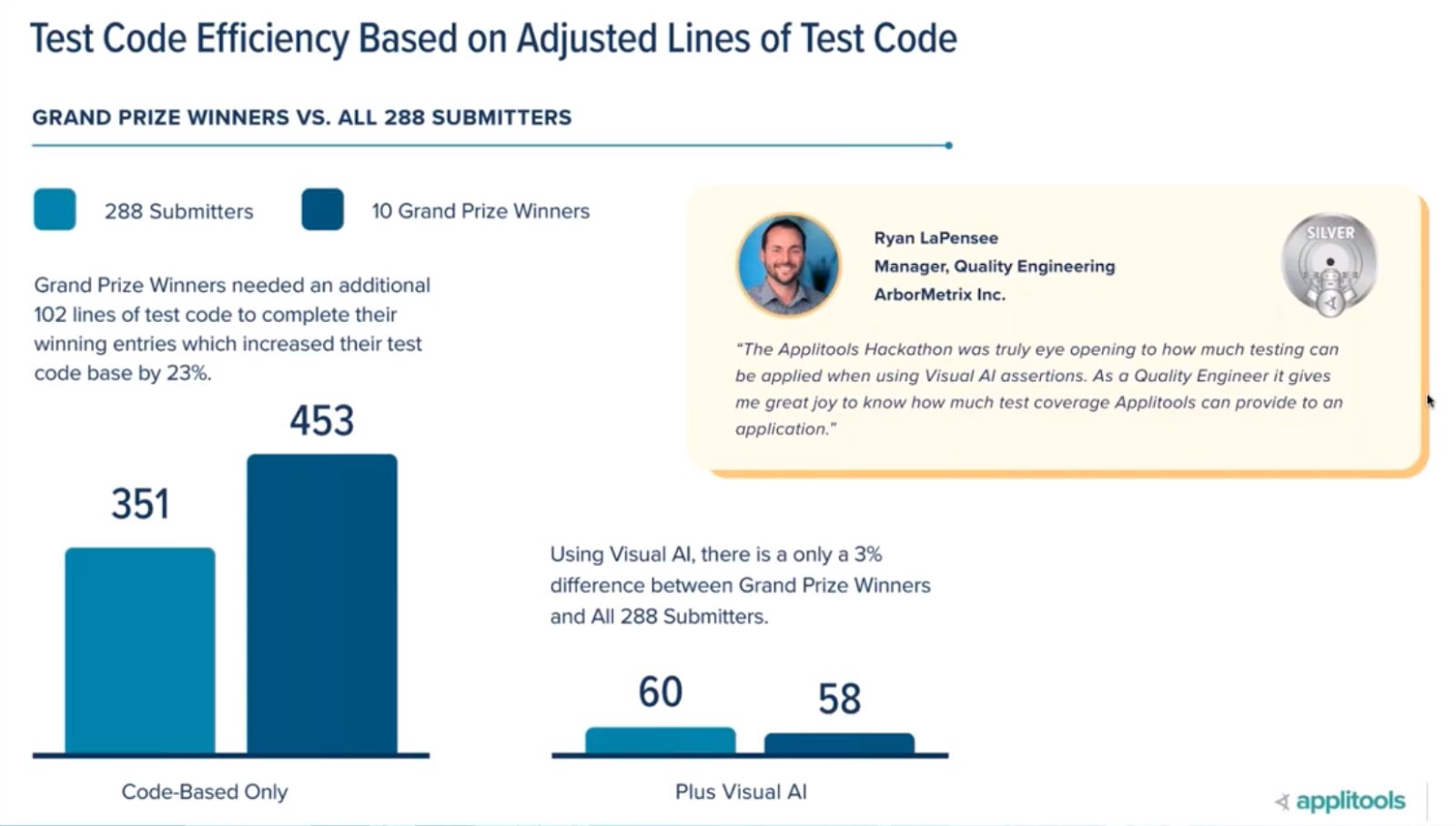
In contrast, with Visual AI, the average coder needed 60 lines of code, and the top coders only 58 lines of code. Visual AI still results in 50 lines of code per hour for the average participant, and 45 lines of code for the winning participant. But, they are much more efficient.
More Stable Code
End-to-end tests depend on element locators in the DOM to determine how to apply test conditions, such as by allowing test runners to enter data and click buttons. Conventional tests also depend on locators for asserting content in the response to the applied test conditions.

Most software engineers realize that labels and other element locators get created by software developers – who can change locators due to intentional change or unanticipated difference. And element locator using Xpath can suddenly discover the wrong relative locator due to an enhancement. The same is true for labels, which can change between releases – even when there is no visible user behavior difference.
No one wants testing to overconstrain development. No one wants development to remain ignorant of testing needs. And yet, because mistakes sometimes happen, or changes are sometimes necessary, locators and labels change – resulting in test code that no longer works properly.
Interestingly, when evaluating conventional tests, the average Hackathon participant used 34 labels and locators, while the Hackathon prize winners used 47 labels and locators.
Meanwhile, for the Visual AI tests, the average participant used 9 labels and locators, while the winning submissions used only 8. At a conservative measure, Visual AI reduces the dependency of code on external factors – we calculate it at 3.8 x more stable.
Catching Bugs Early
Visual AI can catch bugs early in coding cycles. Because Visual AI depends on the rendered representations and not on the code to be rendered, Visual AI will catch visual differences that might be missed by the existing test code. For instance, think of an assertion for the contents of a text box. In this new release, the test passes because the box has the same text. However, the box width has been cut in half, causing the text to extend outside the box boundary and be obscured. The test passes, but in reality it fails. The test assumed a condition that is no longer true.

Visual AI catches these differences. It will catch changes that result in different functional behavior that requires new coding. It will catch changes – like the one described above, that result in visual differences that impact users. And, it will avoid flagging changes that may change the DOM but not the view or behavior from the user’s perspective.
Easier to Learn than Code-Based Testing
The last thing James shared involved the learning curve for users. In general, we assumed that test coverage and score on the Hackathon evaluation correlated with participant coding skill. The average score achieved by all testers using conventional code-based assertions was 79%. After taking a 90-minute online course on Visual AI through Test Automation University, the average score for Visual AI testers was 88%.
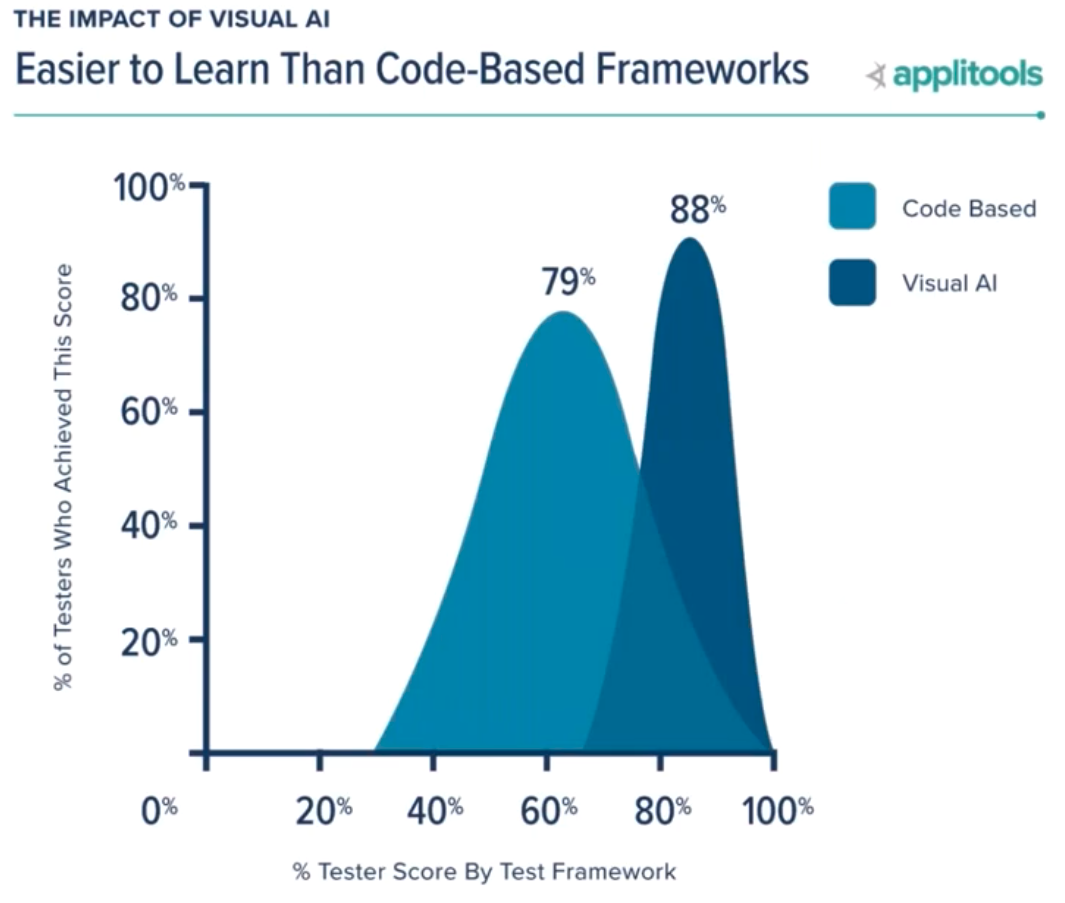
Because people don’t use visual capture every day, testers need to learn how to think about applying visual testing. But, once the participants had just a little training, they wrote more comprehensive and more accurate tests, and they learned how to run those test evaluations in Applitools.
What This Means For You
James and Raja reiterated the benefits they outlined in their webinar: faster test creation, more coverage, code efficiency, code stability, early bug catching and ease of learning. Then they asked: what does this mean for you?
If you use text-based assertions for your end-to-end tests, you might find clear, tangible benefits from using Visual AI in your product release flow. It integrates easily into your CICD or other development processes. It can augment existing tests, not requiring any kind of rip and replace. Real, tangible benefits come to many companies that deploy Visual AI. What is stopping you?

Often, learning comes first. Fortunately, Applitools makes it really easy for you to learn Visual AI. Just take a class on Test Automation University. There is Raja’s course: Modern Functional Test Automation through Visual AI. There is Angie Jones’s course: Automated Visual Testing: A Fast Path To Test Automation Success. And, there are others.
You can sign up for a free Applitools account. Using Applitools helps you understand what you can do With Applitools.
Finally, you can request a demonstration from a sales engineer.
At Applitools, we let users make the case for the value of our Visual AI solution. We hope you will get a lot out of trying it yourself.
For More Information
- Modern Dev Teams Are More Efficient Than Ever — Quality Engineering Should Be Too.
- UI Tests In CICD – Webinar Review(Opens in a new browser tab)
- The Impact of Visual AI on Test Automation Report(Opens in a new browser tab)




