I wanted to know about web element locators. In my free time, I am taking courses on Test Automation University, sponsored by Applitools. We are getting some of the best minds in test automation to present their approaches to testing web software. You may have read my review of Amber Race’s course on API testing.
If you’re looking to go from manual testing to test automation, you need to know about web element locators. I took Andrew Knight’s course on Web Element Locator Strategies to learn about how locators play a huge role in test automation – or just testing in general. Andrew is also a star teacher, consultant, and practitioner in the areas of software development and test. You can read his blog at www.automationpanda.com. And to find out more about the course, read on.
[Author’s note: I now get why all his example locator tests are duckduckgo.com searches are for “Giant Panda.” Giant Panda. Automation Panda. Aha!]
What Are Web Element Locators?
Back when I started out in technology, I worked for a company that made test equipment for computer chips. For chips, the interfaces are pins, and while you try to exercise the chip for functional test, you did so through the pins. To measure behavior, you did so through the pins. The pins were the locators for the device under test.
With web software, the inputs and outputs can be identified by web element locators. If you are an experienced tester, you’re probably thinking, “Gee, Michael, we knew that!” In fact, if you’re an experienced tester, you probably have lots of experience dealing with element locators. But, this course isn’t for you. The meets the needs of people learning about web element locators.
So, I assume I scared off the experienced people, leaving you – a reader who wants to learn about this approach to testing.
Web Element Locators provide software identifiers select and validate elements of the code that you are testing. I am being specific and deliberate with this description, as the terms matter. Locators are software reference points that allow you to pull data from and push data to a web page and measure its response. It’s important to have good locators.
Why Do Web Element Locators Change?
Unlike device pins, locators as identifiers might change from build to build – depending on coder practice. Identifiers might be identified in HTML code by ID or Name and can be recognized directly. Others might be identifiable by Class name. At times, the only identifiers are CSS, XPATH or text on the page. You may have to be creative.
On a given web page, any object can be identified explicitly through the domain object model (DOM) relative to the root <html> of the page. Andrew made this clear – it’s impractical to use the explicit call relative to the DOM for two reasons: complexity and fragility. The DOM can be nested many layers deep, and a call through multiple layers every time is both unreadable and unnecessary. And, using the DOM location will fail when the code changes.
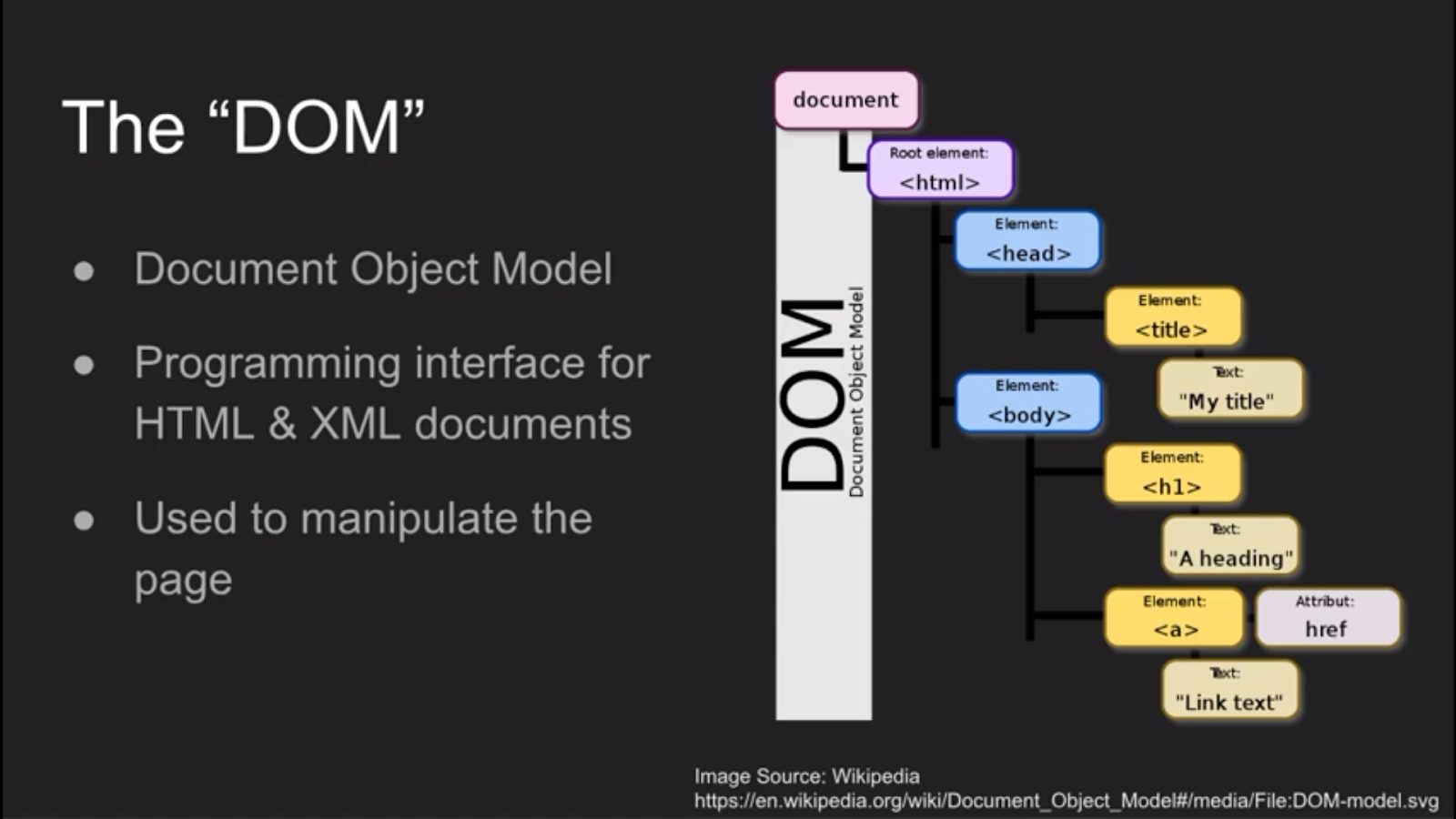 Often, developers create unique identifiers to control the behavior of a page through JavaScript. Good testing will validate the code behavior and utilize similar identifiers. Other times, developers use identifiers to explain the behavior of their code – again, reasons to use these identifiers.
Often, developers create unique identifiers to control the behavior of a page through JavaScript. Good testing will validate the code behavior and utilize similar identifiers. Other times, developers use identifiers to explain the behavior of their code – again, reasons to use these identifiers.
Sometimes, developers use the same identifiers for different elements in a table or other programmatic output. In such cases, the identifiers can be indexed (so long as they are used consistently) so that test code can be the “Nth” instance of a given identifier.
Valuing Consistency In Identifiers
Andrew made it clear that locators are code-generated. Sometimes, coders define an application with consistent IDs or names for objects that don’t vary from release to release. These identifiers are excellent for building test automation. Everything else that depends on CSS or XPath – or even named fields – can vary when a coder updates an app.
Andrew didn’t say, but I inferred from his course that there is a separate Design for Testability skill set that developers must possess to make any test automation work across releases. In other words, when developers add IDs, names, or Class names, they should ensure that such names are used uniquely and/or consistently from release to release on functions that behave identically between those releases. Since testing depends on those identifiers, any change will cause tests to fail.
A large part of the course goes through specific kinds of identifiers and their relationships. For instance, I can look for exact matches of identifiers. The most obvious kind is “id=” attributes, which, according to HTML standards, must be unique on a given page. The “name=” attributes are added by programmers for input-related elements.

Added Benefit – Learning Developer Tools
The course uses Developer Tools in Chrome to help show how different identifiers are used to identify specific elements in the DOM. There is a comparable package on Firefox. I had never used Developer Tools before, and I found them to be quite useful and interesting. You can launch Developer Tools from the Chrome menu (View > Developer > Developer Tools). You can use a keyboard shortcut. On my Mac, I launch Developer Tools by pressing CMD-Option-I at the same time. And, lastly, you can use the three dots at the top far right of the Chrome Screen to display the internal menu and pull down to (More Tools > Developer Tools).
My big tip for you is to know that there is a Find function in Chrome Developer Tools. You can display the Find box in Developer Tools, but only by hitting CMD-F (ctrl-F on Windows or Linux) while the Developer Tools is in focus. So, to generate the Find box, click somewhere in Developer Tools. Otherwise, you’ll open up the find box for the screen you’re inspecting. I spent a large amount of extra time learning to use the Developer Tools package in Chrome.
Once you launch Developer tools, you can click anywhere in the text and see what gets highlighted on the web page. Similarly, there is a selection tool (looks like an arrow cursor in a box at the top left of the Developer Tools screen). You can select anywhere on the page and highlight the corresponding text in the HTML. All in all, it’s a great toolset to learn. We only touch on Developer Tools can do in the course.
Practical Examples Of Identifiers
The course finds web element locators by inspecting the https://www.duckduckgo.com/ search engine.
On a page with search results, the box for entering a new search has the id attribute:
id=”search_form_input”,
which is unique on the page. However, the name attribute for the same box is
name=”q”.
That could be simpler. It could also be more fraught between builds – depending on how the box got the name “q” in the first place.
A third identifier is the class name. Class names can be great ways to find content. Class names are not always unique – and occasionally they can point to hidden text. Much of the course goes through these identifiers and helps you understand how to select the right one for your application.
Once you’re using identifiers, you start realizing that not everything can be identified uniquely by names. Some names require either using CSS to uniquely identify a part of the DOM, or you can explicitly call relationships using XPATH. Both approaches are even more tied to code and require you to double check the structure for your test after builds that affect the code on which you base identifiers.
I’m not going to go into the details – those are best left for the course. But, suffice to say, you have plenty of identifiers in HTML and CSS to ensure that you can apply inputs to your application and measure the application responses consistently.
Using Identifiers – Codeless and Coded
The final chapter of the course goes into the meat of the topic – actually using identifiers as web element locators. After you select an identifier, you may test with it. You use identifiers:
- for input fields to create input data.
- for buttons to drive actions and behaviors on the page.
- to validate output fields.
There are two kinds of testing engines. One is codeless and lets the testing engine inspect the DOM and, based on the region in which a user clicks or focuses, find a unique identifier for the text box or button to initiate activity. The other is coded and uses a programming language interface to initiate tests and measure responses, using identifiers from HTML code to control behavior. Coded engines, like Selenium, Appium, Protractor, and WebDriver.IO, use WebDriver. WebDriver is a remote control interface that provides remote control of web browsers.
Choosing Codeless
If you’re choosing between codeless and coded engines, think about your current technical skill set and background. Whether using Java, JavaScript, Python or another language, coded engines require coding skills. If you come from a manual test background and don’t know how to code, you likely have a steep learning curve to become proficient with coded tools. Codeless engines have the advantage that they are simpler to learn and run. However, you may still need coding skills to inspect your tests when they fail and figure out what is going wrong.
When codeless tests encounter updated code and identifiers, the new identifiers can cause the codeless tests to fail. Some test engines, like Selenium IDE, try to find multiple locators for a given object, so that a change in one locator is not an immediate failure.
Choosing Coded
If you’re already a programmer, you will feel right at home with coded test engines. You might be able to use your choice of programming language, or a language you know already, to write tests.
Andrew’s course goes through two test examples using the DuckDuckGo.com website. The first example he writes in Java, and it describes all the tests he wants to apply, the waits between entering data and getting a response, and then measuring response. He writes this all out manually in Java. This looks like a script of instructions with locators. As the testing grows, the number of scripts can grow – and the number using the same locator in different places can grow. Which means all the scripts need to change if one locator changes.
If you’re a coder, you’re probably thinking,
“I bet maintaining this script is a pain in the …”
Then, Andrew makes all of you developers happy by saying, effectively,
“There is a better way.”
Andrew goes through the Page Object Model, which helps separate the test code from the test objects. Effectively, you create a file with a class of objects for finding web elements, and either entering data in them or verifying the response. You create a separate class of tests that actually use the elements class and manipulate the tests. So, if the development team updates the page locators, you keep the same test code and simply update the locators.
Huge sigh of relief.
Here is an example of Page Object code in Java from Andrew’s course:
Using Applitools
One thing the course didn’t cover is how Applitools can help. Yes, you can use test code to both apply a test instruction, wait for a response, and measure the result. That’s a great way to think about applying tests to web pages.
Of course, even if you test programmatically, you need to make sure that each object on the page is rendered as expected. Different content, unexpected color or visual images, and other visual errors require painstaking coding to ensure they don’t haunt your code. That’s where Applitools comes in.
Applitools can easily integrate, with both coded and codeless tools, to help take visual images of the output from each test step and compare it with a baseline. While your functional code ensures that your main function behaves as inspected, Applitools is ensuring that everything else behaves equally well.
If you are looking for a codeless solution, Selenium IDE has multi-locators built-in. It records several different ways to locate an element. So if one doesn’t work, it will try another. Click here to read more about Selenium IDE.
Finally, visual testing lets you reduce your use of locators dramatically. This means less test script code to maintain. Of course, Applitools is a great way to do visual testing.
What I Take Away
Through this post, I want to share with you a taste of what I got from the course. Being some 20 years out of programming, I make all the rookie mistakes of someone new to this field. And, honestly, that sucks. I like being the smartest person in the room (and, yes, I know it’s a common failing among engineers – we all want to be that person). But, I’m learning as I go forward.
My takeaways are that there are lots of different identifiers out there to control the behavior of test tools. Not all are created equally. And, not all are created.
A helpful development team will create unique identifiers for each element you might want to test. Those developers will think about testing do so because they are writing the same tests themselves. Those coders moonlighting as test developers might actually be you – as you are a part of the development team yourself, and you’re using this course to help build better tests or improve code testability.
You might be finding, too, that you’re not as connected with the development team – the coding has been done long before you immerse yourself into the test process. This course helps you write tests even when you write tests independent of the development team.
As always, I get to show how smart I am by adding my showing off my certificate of completion:

Thank you for the course, Andrew Knight!
What Next?
- Take one of the great courses on Test Automation University.
- Setup a live demo with us, or if you’re the do-it-yourself type, sign up for a free Applitools account and follow one of our tutorials.
- Read another blog.




