The other day, I was supposed to meet a colleague for drinks at the local bar. He was a bit late, as he got delayed at work. When he arrived at the bar, after a drink or two, he asked if I could take a look at the problem he had. “Sure, why not,” I said.
First, some background: we’re both in the testing business. I am a software developer at Applitools where I develop visual UI testing software tools based on artificial intelligence algorithms. My friend is a test automation engineer working on automated testing in a web SaaS company. One of his responsibilities is to make sure new versions don’t have any unexpected bugs.
My friend explained that his visual UI tests started failing for no apparent reason. There weren’t any changes to the website, but all of a sudden his tests were failing. Like all visual test scripts ever written, they worked pretty much like this:
- Browse to a page in their web app
- Take a screenshot of the page
- Compare it to a baseline screenshot from a previous test, which was manually validated and added to Git.
I took a look at the before and after images of the test. The before image was saved in Git to compare with the images generated as part of the test. Comparing them manually, I was sure I had one too many drinks, because they were exactly the same! And yet the image comparison failed!?
See for yourself. Here is the baseline image, which they stored in Git:

And here’s the image generated by the test:

Same, right? Looks totally the same, even to my now sober eyes. But comparing them using pixel-based bitmap comparison algorithm they use, this is the result my friend got:

It wasn’t just a one or two-pixel difference. The whole thing was totally messed up. It was filled with more red dots than a Roy Lichtenstein picture. In fact, most pixels were different.
Crazy!
And while we puny humans couldn’t see any difference whatsoever – the algorithm found that most pixels were changed.
This was going to take another round of drinks.
So we started to look at the test for any changes related to this. But we didn’t find anything that would affect this. So we looked at the test’s container infrastructure. I asked him how he ran the browser that was used in his automation and visual tests, and he explained that they were using a containerised headless Chrome for their automatic tests — straight out of Docker Hub. The Dockerfile of his image looked similar to the following Dockerfile:
The culprit was sitting right there! Specifically, the apt-get command on line 6: apt-get install -y google-chrome-stable.
This command meant that they were using the latest version of Chrome—at the time the Docker image was created. Apparently, one of their engineers decided to rebuild all the images, which caused the Chrome version to update from version 67 to the latest stable version, version 68.
So we did what any two geeks would do in a bar: we dived into Chrome’s software change history to see if we find any relevant change. But alas, we went too deep and got lost in the number of changes. It made sense to stop there, as it is expected that there will be changes in the way browsers render elements on the page: fonts, images, layout (especially with responsive elements), CSS directives, etc. The amazing thing is that Chrome totally changed the way images are presented, and yet they still looked the same to a human eye. Why they did that is not clear. Performance reasons, maybe? Who knows?
To fix the problem for the future, we decided to freeze the Chrome version they used, and tag the Chrome Docker image with a version number—for future reference and comparisons.
But meanwhile, my buddy (the day after), needed to fix his tests. And while my buddy started replacing reference images across the board — check screenshot for correctness, copy the image from the ‘actual’ folder to the ‘expected’ folder, repeat for each of the hundred screenshots — I figured I should check if using Applitools Eyes, instead of their simplistic open source pixel-based image comparison library, would have made a difference.
So I ran an artificial test, with the images of the dogs we had, and used the Applitools image comparison API, which enables us to compare images without needing to take screenshots of web pages, but uses the same comparisons as for regular screenshots. I started with ‘Exact’ mode, which also uses a pixel-wise image comparison method, similar to the one most open-source and commercial image comparison software tools out there use:
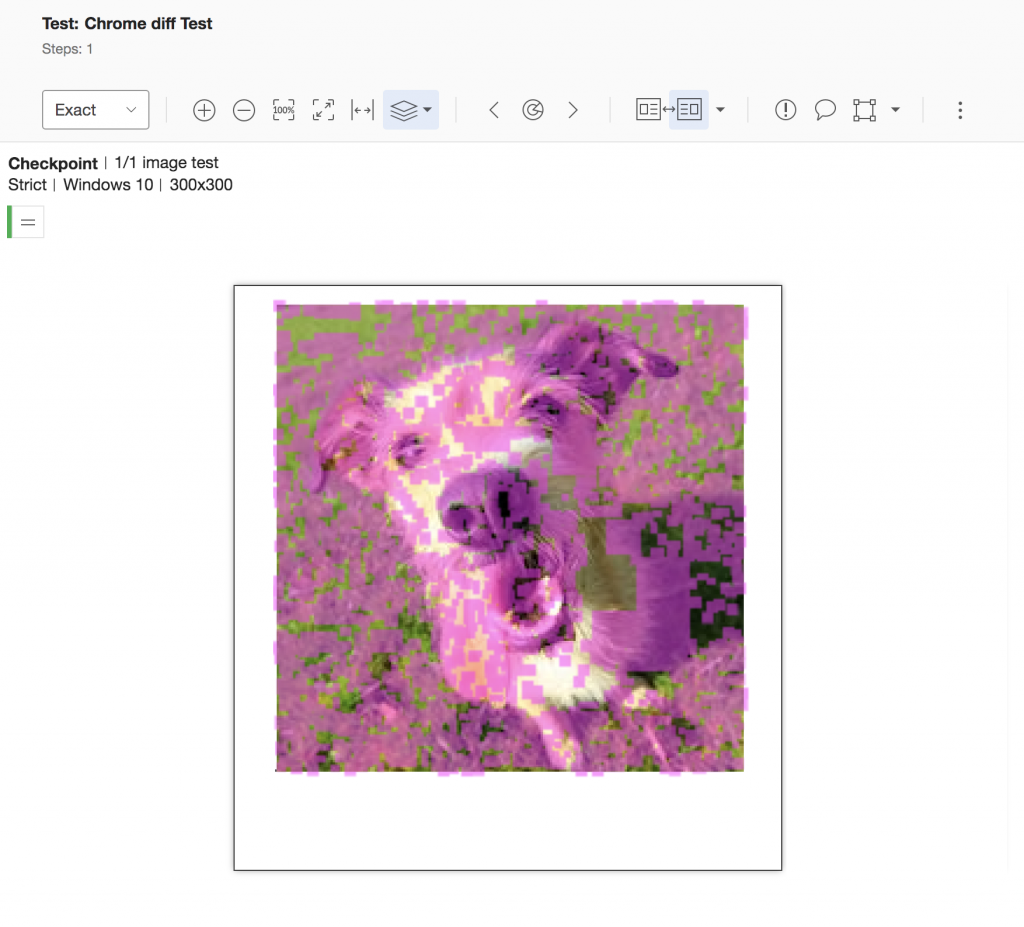
OK, no surprise there. It behaves exactly the same as my friend’s image comparison tool. The human eyes see no difference, but in terms of pixel comparison, it’s all changed.
Let’s take it up a notch, and try to use our AI based ‘Strict’ image comparison algorithm, which ignores changes not visible to the human eye:
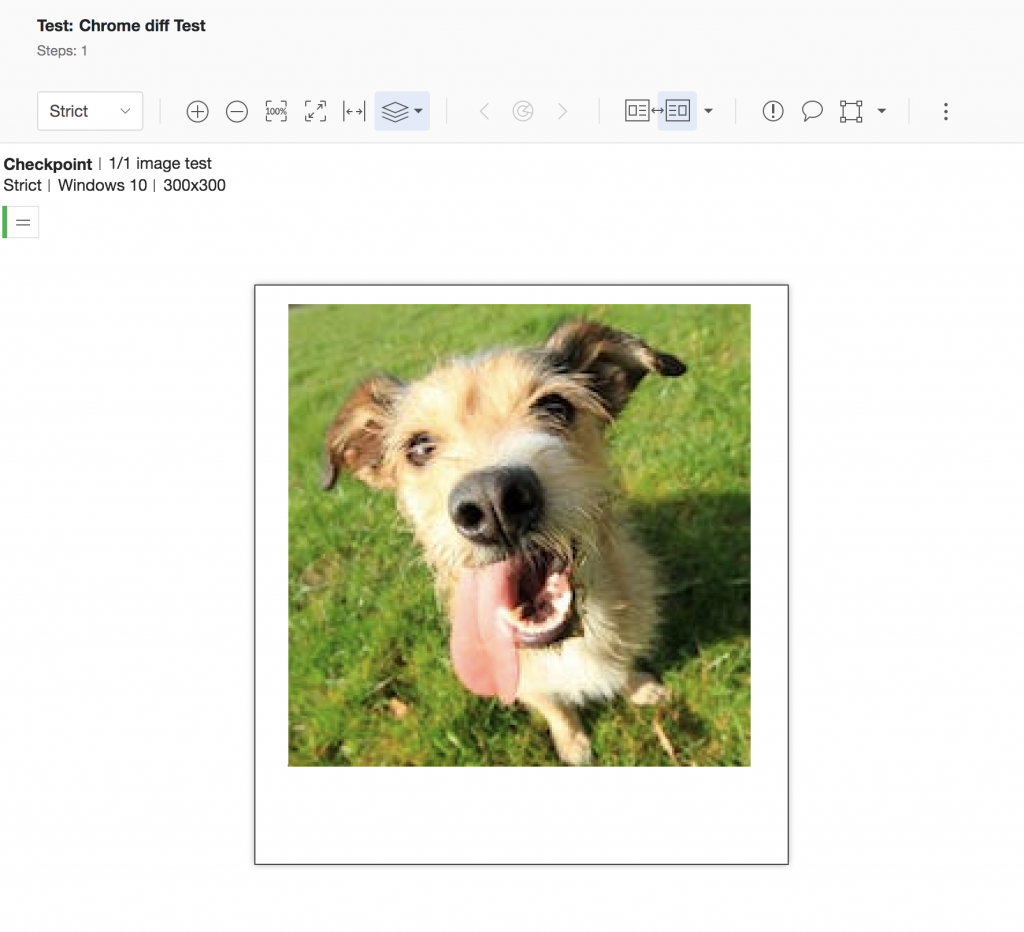
And voila!
From Applitools Eyes’ standpoint, the images are the same—even if most of their pixels are different. This is because Applitools looks at screenshots the way a human would, and ignores differences: just like a human eye would.
That’s the whole point of using an AI based image testing tool like Applitools: to see your apps the way your users do. And avoid a bunch of false positives that keep you at the office (or a bar) longer than you should.
There are plenty of reasons why not to use simplistic image comparison tools, but the point is, if they had used Applitools instead of running their own image comparison tooling, we could have been talking about other stuff at the bar.
Next time, drinks are on him. 🙂
To read more about Applitools’ visual UI testing and Application Visual Management (AVM) solutions, check out the resources section on the Applitools website. To get started with Applitools, request a demo or sign up for a free Applitools account.