This list of pitfalls to avoid when testing in production serve as my notes on Amber Race’s Webinar: The Joy of Testing in Production
If you don’t already know her, Amber Race is a rockstar. She’s a senior software development engineer in testing (SDET) at Big Fish Games. Through her amazing experiences, she continues to gain wisdom on a subject often thought of as taboo in the world of software development: testing in production.
Now, some people think that testing in production is bad, which results in this common meme:

Amber presented recently in a webinar why testing in production is actually a good thing. These are seven key takeaways from her webinar.
But first, some background: BigFish uses API-delivered services to power its games. Amber knows that real-world use can create test conditions she could never recreate in her lab. This is why it’s essential to test in production — as well as in development, of course. Also, monitoring in production has helped her team pinpoint areas of inefficiency that ultimately led to better results.
Pitfall 1 – Willfully Disputing the Need for Testing in Production
The first pitfall to avoid when testing in production is ignoring the need. Amber noted that there is still a hopefulness that testing ends once code is in production. “There’s a traditional view that once you put your stuff out in the world, you’re done. But, of course, you’re not done because this is the time when everybody starts to use it. It’s really just the beginning of your work when you’re releasing to production.”

There will always be one that gets away…
Every time a customer opens an app or a webpage, they are testing to see if it opens properly, is responsive, etc. Amber notes that even if you *think* you are not testing in production, you already are: “Instead of thinking that testing and production is something that you should be doing, you should be thinking that it’s something that’s already happening every moment your application is being used.”
Every application depends on behaviors and environments that may fail when exercised. And, yet, the complexity of applications demands that they be tested “sufficiently” for behavior with a realistic understanding that testing will not cover every real-world use case.

The pitfall here is being dogmatic about correlating production outcomes with how well your QA team does their job. All unit and functional tests must be completed and show that the application works according to a set of environmental metrics. The team needs confidence that the design works as expected in hypothetical customer environments. That’s not the same as knowing the real world.
Pitfall 2 – Overscoping Tests Needed In Your Sandbox
Sandbox testing can give you a false sense of security. They can also consume lots of resources that provide little incremental value. Amber called out this as the next pitfall to avoid when testing in production.
Testing within a “sandbox” doesn’t fully address the complexity of the number of environments, devices, browsers, operating systems, languages, etc. that exist. Amber exemplifies this point: “I counted up on one of our devices and we had in a certain snapshot of time 50 different Android devices. Forty-five different iOS devices, the combination of the device itself and the iOS version. So there are almost 100 different kinds of devices alone. And, that’s not even considering all the network conditions – whether people are playing on a fast Wi-Fi network, or they’re on 3G or they’re on 4G, or they have some spotty connection that’s in and out. You cannot possibly cover all the client combinations in a sandbox.”

If you are thinking the cloud might help you better replicate a production testing environment, think again, Amber says: “Even if you’re able to replicate your production environment in the cloud, does your test user base match production? For example, in the case of the service we provide, there’s a constant load happening of a quarter of a million players every day playing our games constantly happening in the background. We can’t replicate that in a test environment.”
So the pitfall to avoid is thinking that the breadth of your sandbox testing covers all your functional and behavioral environments. Instead, ensure your coverage at the sandbox level exercises your code under load and one or more hypothetical production environments. To be clear, those must pass. But, your tests will never represent the array of environmental and load factors that will impact the behavior of the production application. If you are still expecting you will catch all issues in QA, you need to let go of that idea.
Pitfall 3 – Not building production monitoring
Amber pointed out that another pitfall to avoid in production testing involves proper tooling. Application developers need the right tools for production monitoring.
She talked about one API that her company was using on one of its largest production games, and this API was using a non-standard interface. It wasn’t JSON or SOAP – it was BSON. There weren’t any standard monitoring tools for this API service behavior – and was jumping all over the place. There were failures in production that could not be explained by logs or other metrics. So, she needed a way to help the team understand what was happening with the service.
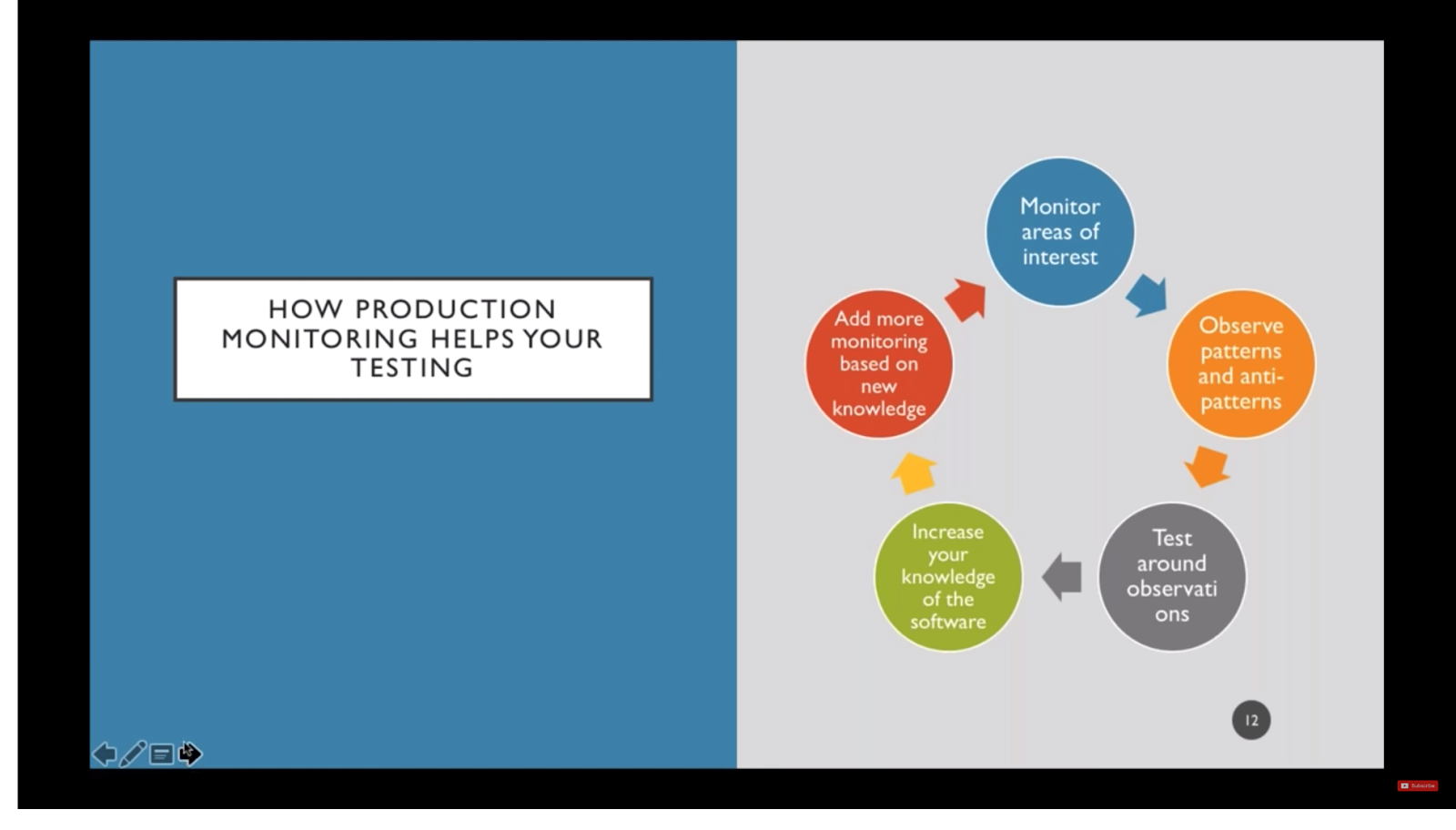
She explained that code in test is like practicing your steps preparing for a night out dancing. You work on your moves, you look good, you check yourself out in a mirror. But, once you get the club, the environment turns into “a giant mosh pit of users doing all kinds of combinations and all kinds of configurations you would never ever think of.” What is the solution? Monitoring in production! So, you really need to build monitoring into production.
Here are some top practices Amber suggests:
- Monitor your areas of interest. Start small: “ “You can just start with one thing. Like, add counters onto your API usage and calculate the API usage patterns you observe.”
- Take it to the next level. Amber would calculate the usage by API and figure out API dependencies by determining the order in which they were called. “Just by observing what’s really happening you can prioritize your testing. You increase your knowledge of the software.”
- Know which dependencies are in your control. “Once you have dependency information you can add more monitoring around what’s going on. For example, if you have an authentication solution and that is calling a third-party service you might start by looking at how long authentication takes.”
- Be aware that monitoring has costs. All monitoring will consume resources that require processing, memory, and network.
- And, to get to some metrics, monitoring may need to be built into the code at the development or the operational level.
Pitfall 4 – Not Knowing the Monitoring Tools You Can Install
Yet another pitfall to avoid is a lack of information for tools that can store production metrics. The easiest type of metric storage is a log file. Amber discussed that one of the most well-known log file search engines is Splunk. Another is the ELK (ElasticSearch, Logstash & Kibana) stack. The value of any of these tools depend on depend on the metrics you need being found in the log files.

The next type of metric storage is in a database. Graphite is a tool for stats extraction and analysis from a database. StatsD and InfluxDB are other tools for database data extraction and analysis. Know that this kind of testing will require additional coding.
Finally, Amber discussed both Grafana and Kibana as visualization tools. These are all tools that can be either purchased commercially or, in some cases, downloaded as freeware.
At BigFish, Amber and her team used Graphite and Grafana for API behavior visualization. An example of this work is below:
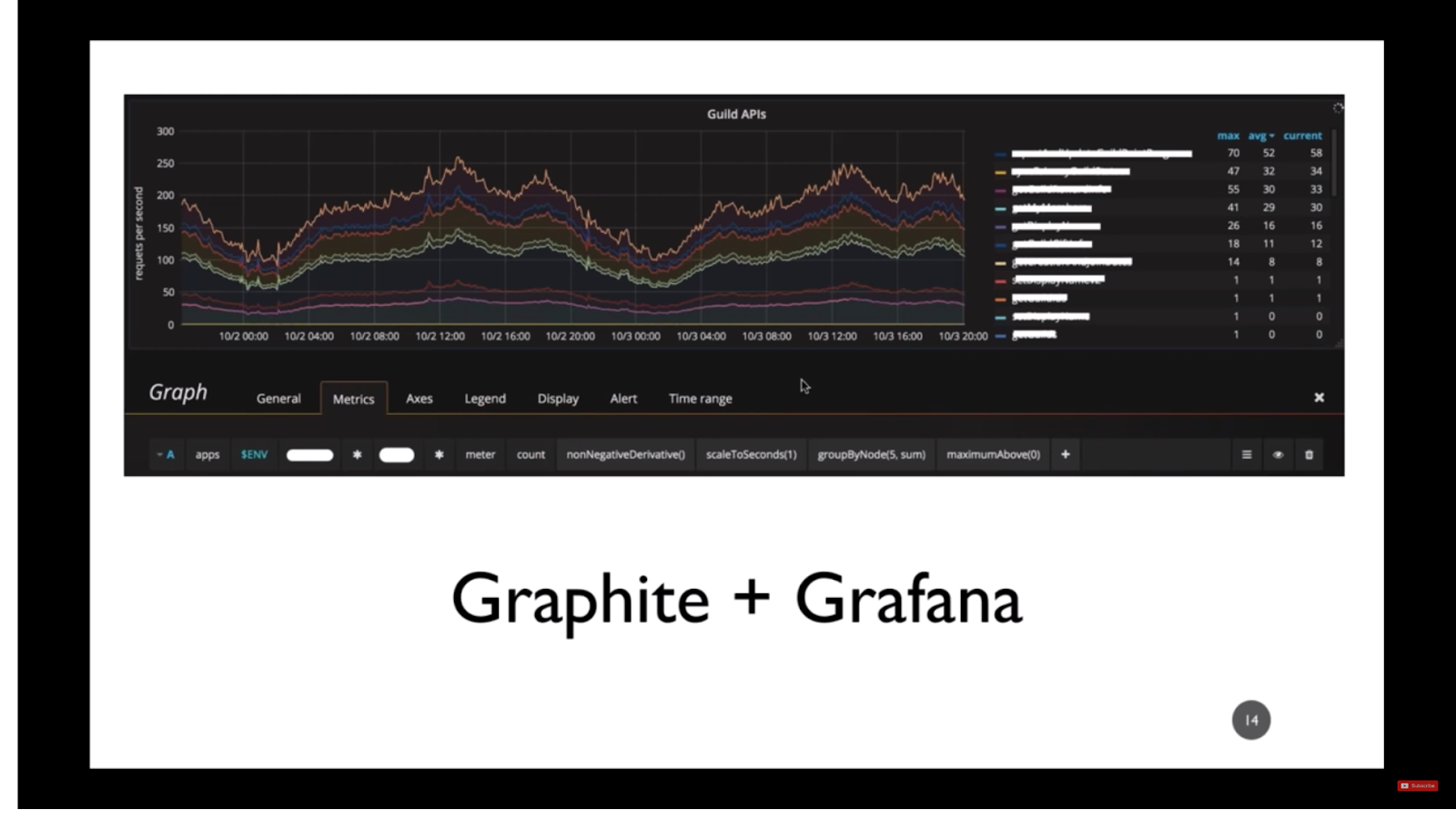
Bigfish chose Graphite and Grafana for the following reasons:
- “The stack was already in use by Ops. “Always ask the Ops team what they’re using,” says Amber.
- Instrumenting the code was easier than fixing the log writers
- There is a lot of flexibility in the Graphite query language
- Templates make Grafana really useful.
- “Pretty graphs are nice to look at.”
Again, the key is to look at the ability to add tools that are easiest, instrument the right metrics, and begin to monitor.
Obviously, you need to know what to monitor and how best to show the values that matter. For example, If you can install a timer for accessing a critical API, make sure you can graph the response time to show worst cases, statistically. Graphite can show you the statistics for that metric. The 95th percentile value will show you how slowest 5% of your users experience the behavior, and the p999 latency will show you how 0.1% of your users are seeing things.
Realize that 0.1% is 1 out of every thousand. If you only have 1,000 users, you might think you can live with one user having this experience. If you have a million users, can you live with 1,000 having this experience? And, if you have 1,000,000 users and they, on average, call this API 10 times during a typical session, they have more like a 1 in 100 chance of hitting this worst-case behavior. Can your business function if 10,000 customers get this worst-case behavior?
The key is to know what you are measuring and tie it back to customers and customer behavior.
Pitfall 5 – Not Learning From Monitoring
When engineers insert production monitoring, said Amber, they may think they are done. This is the next pitfall to avoid when testing in production: failure to learn from monitoring metrics.
The keys to understanding monitoring are knowing that you need to see what is important. For instance, when you want to observe performance, you need to monitor the latency of calls and their frequency. When you want to drive efficiency, you can look for frequently-invoked calls (such as error handling routines) which imply that your code requires underlying improvements.
After implementing their own monitoring tools and processes, Big Fish Games was able to find concrete ways to improve their system. One of the big takeaways was learning that they had API behaviors that were generating errors and then discovered that the errors did not result in user problems.
Amber noted: ”We would have calls that the game was making that failed every time. The calls failed because maybe it was an older client or we had changed the API. Regardless, it was an invalid call. So that’s a waste of time for everybody, it’s a waste of time for our service. It’s a waste of time for the client. Obviously, this call was not necessary because nobody had complained about it before. So having them remove those calls it’s saving traffic on our site. It’s saving network traffic for the player. It’s savings for everybody to get rid of these things or to fix them.”
Additionally, Amber and her team found that certain API calls caused obvious load issues on the database.
“We had another instance where the game was calling the database every 30 seconds. And it turned out 95 percent of the time the user had no items because the items in question were only given out by customer service. So we’re making all of these database requests and most of the time there’s no data at all. We were able to put some caching in place, where we knew they didn’t have data we didn’t hit the database anymore and customer service would then clear that cache. The point is that this change alone caused a 30 percent drop in load on the database.”
Pitfall 6 – Becoming Monitoring Heavy And Forgetting Value
The sixth pitfall to avoid in production testing involves failing to build high value, actionable monitoring solutions.
Once you have metrics, it’s tempting to begin making dashboards that show those metrics in action. However, don’t just dashboard for the sake of dashboarding, Amber advised. Instead, continue to make sure that the dashboards are meaningful to the operation of your application.
Make sure you are measuring the right things: “Always re-evaluate your metrics to make sure you are collecting the data that you want to see and your metrics are providing value.”
Amber explained a critical difference between monitoring and observability. She provided her explanation: “The difference between monitoring and observability is that with monitoring you might just be getting load average but you don’t know exactly what went into that average, whereas when something is completely observable you can identify and inspect specific calls that are happening within that moment of high-performance issues.”
The key, she concluded, is to value metrics and dashboards that let you act and not just wonder.
Pitfall 7 – Not Being Proactive about Performance, Feature, and Chaos Testing
Once you have instrumented your production code, you can use production a test bed for new development. Amber noted that many companies are wary about running production as a testbed. That fear can lead to the last pitfall to avoid when testing in production – not using your production testbed proactively.
No one is suggesting to use production as a place to test a new user interface or graphics package. Still, especially for new services, production can become a great place to try out new code while real-world users are applying load and changing data.
Being able to do performance testing in production is key, said Amber “The number one best thing about testing in production is doing performance testing in production so you can test before your clients are updated to use a new API. You can put it out on your production service and run a load test on that particular API while you have all the background noise going and you don’t have to guess.”
She shared her thoughts on the benefits of feature testing in production: “[With feature testing] you have the real hardware, the real traffic, and the real user experience is happening just in a box. If it’s something you can turn on and off easily then that makes for a very useful test.”
Even chaos testing belongs in production, Amber explained. “Chaos testing is good when you want to see what happens if a particular host goes down or a particular database is offline. With these sorts of network outage conditions, it’s important to see if your flows are working the way they should. You want to test these in a place where you have control rather than letting the real chaos take over. Who wants to be woken after midnight to figure out what’s going on?”
Final Food For Thought
Given that you’re paying attention and not falling into the pitfalls, get ready to add production monitoring and testing to your arsenal of application tests.
Here are a few more musings from Amber that will get you pumped to start testing in production:
- “By observing you can look for new things to look for and you can do this even without a so-called observer to observability solution. Taking in this information is really important for baking more quality into your services and understanding your services and applications better.”
- “The point is not to break things, it is to find out where things are broken. That’s why we’re doing the monitoring in production. That’s why we’re doing this testing is we want to see what’s happening with our actual users and where their issues actually are and hopefully alleviate them.”
- “Most importantly, explore without fear.”

To capture all of Amber’s inspiration on monitoring and testing in production, watch a webinar of her full presentation, “The Joy of Testing in Production”:
https://youtube.com/watch?v=8-ymeVdNxSE%3Frel%3D0%26showinfo%3D0
To visually test your apps before they go into production, check out our tutorials. Or, let us know if you’d like a demo of Applitools.
Other Posts that might interest you include:
- Test Your Service APIs – A review of Amber’s course on Test Automation University
- Automating your API tests with REST Assured – TAU Course by Bret Dijkstra
- Running Tests using REST API – Helpdesk article by Yarden Naveh
- Challenges of Testing Responsive Design – and Possible Solutions – by Justin Rohrman