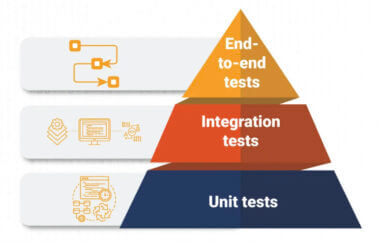
Much is made of the dream flow from continuous integration to continuous testing to continuous delivery to production. Conceptually this sounds great! A developer checks in their code, the code is built, unit tests are executed, the code is deployed to a testing environment, and then the automated test scripts are executed. If nothing fails in the preceding steps, the code is then automatically deployed to the production environment. The users/clients/customers potentially get multiple releases per day, but also potentially get multiple features or fixes per day. We get all of this with no human delay or interaction once the code is checked in. Also, we get all of this with no human oversight and little human insight.
What could possibly go wrong? What, indeed!
Capturing Visual Issues
Let’s assume we have a production system with which humans will interact. One thing that could go wrong is the user interface could be all “messed up”. Perhaps all the text and the background are now royal blue. Blue on blue is difficult to read, to say the least; our users would not be able to use the site. It could be worse, though: what if our #1 competitor’s well-known logo and product color is royal blue. This would be awkward at best. At worst? Perhaps we are infringing on a competitor’s trademark and are now subject to legal action.
Oh, wait, automated visual testing would have caught that. Correct! Automated visual testing would have caught that plus a slew of other visual and formatting issues. But, like most testing and automation techniques, visual testing can’t catch everything a human would because automated visual testing isn’t, well, human…
Capturing Timing Issues

What if a transaction takes longer than it should or than it did last time? Oh, well, we can check for that in our scripts. Cool, cool. Do we have test scripts that pause mid-flow for 30 minutes because one of our kids threw a handful of Legos at the other and it was the end of the world as we know it? Uh…oh…no…, we can add a script for that. Can we add scripts to pause at every possible place in the flow? Probably not; we probably can’t even think of every possible place in the flow. Spoiler alert: our users do these things, so do their kids, pets, and roommates.
Can we think of everything? Likely not. We’re human.
Cost of Change and Cost of Failure
Now, there’s nothing inherently wrong with the process I outlined above. As always, it’s about being responsible. If developer-check-in-to-prod works for your organization, then you should do it…provided you understand the risk. This risk manifests in two big buckets: cost of change and cost of failure.
The cost of change is something that’s discussed a lot. What does it take to debug an issue, fix it, then run the fix through the pipeline to get it to production, and therefore, to the users? That’s a very basic cost of change calculation: the cost of the effort required to determine a fix and get that fix out of the door to the user. Oh wait, while we’re addressing this issue, we’re not addressing other issues and we’re not working on new capabilities. These are costs as well; they’re referred to as opportunity costs, i.e. the cost of not addressing Thing B because we are working on Thing A. The math on the cost of change starts to become more involved because we’re now accounting for the impact of addressing an issue.
Let’s take the story further; consider a retail company. Most retail companies that have a brick-and-mortar storefront also have an eCommerce capability via a website and a mobile app. The cost of change on the website is generally low. When a customer encounters an issue, the retailer may lose that customer or perhaps it will give a discount to that customer to make up for the poor experience, but the retailer can generally minimize the number of lost customers by quickly deploying a fix precisely because the cost of change is low.

Contrast that cost with the cost of change for this retailer’s point of sale (POS) system. Changes to a POS system have downstream impacts that aren’t immediately obvious. Consider a retailer that has a large number of stores but that has a very small per-store number of employees, say, ten employees per store. Each employee must be trained on new or changed POS features; the number of training and ramp-up hours per change may not be insignificant.
Now suppose we found an issue with the POS release and the resolution for this issue requires a change in the workflow. Though the training cost will likely not be as large as the original cost, there is still a non-zero training cost to deploying the new software for use. Of course, when the number of employees that use the POS system is larger, the training and retraining costs are larger as well. As we can see, the actual cost of change can be higher than it appears on the surface.
Imagine further that this POS software has an outage…on Black Friday. There will possibly be 10’s or even 100’s of people in a store, all of whom are all inconvenienced by the outage, and many of whom will be expressing their frustration on social media. Here, we see that there is a cost involved that’s in addition to the cost of change; issues, problems, and failures have a cost as well.
Framing Costs of Failure Issues
The cost of these issues, problems, and failures is something that seems to be discussed less frequently. What is the cost of failure? It’s the cost to the business of an issue, i.e. failure, in the system. In some cases, it’s probably rather small. If we’re producing a 99-cent mobile game and a user encounters an issue, we may lose that user but, in the grand scheme of things, we may not really care because we didn’t lose appreciable money. It’s ugly to say, but when discussing business, it’s generally accurate. We may lose that customer and perhaps some of their friends, but we’re probably not hinging our house payment on that one game sale.
Contrast the 99-cent game example with a package delivery company. This company will likely have a website for its customers to arrange pickups and deliveries. The cost of change is probably relatively low if there’s an issue on the website; the cost of failure, however, could be catastrophic. What if legal documents for a corporate sale were delayed, or worse, sent to a competitor by mistake? What if an undiscovered error in our system causes the company to fail to deliver life-critical medical supplies, or, say, a donor organ? Catastrophic, to be sure. The cost of this failure is unacceptably high.
Even in the cases where there is no loss of life, there can be tangible financial costs to failure as well. Companies often have contracts with their clients that contain service level agreements (SLAs). Violation of the SLAs can require penalty payments or a return of previously paid fees when our systems are “insufficiently performant”.
Conclusion – Assess Your Costs and Risks
As with most concepts in technology, there’s nothing inherently wrong with “check-in and deploy to production”. Companies are doing this and seem to be content-to-happy with the business results. That said, in all circumstances, we must be responsible with our automated approaches. We must understand the risks we are undertaking, and the risk tolerance we have. Without these self-assessments, we won’t be prepared for the consequences for the risks we unknowingly undertake.
Like this? Catch me at an upcoming event!