What are the drivers of productivity on your QA team? How do you increase coverage and speed across a range of platforms?
If you work in QA, you might experience the whipsaw of a development team pushing ever more quickly toward releasing software, and a broad range of platforms on which your apps must run.
With today’s standards, developers can develop once, test in development, and assume they are done. Legacy QA productivity remains limited because QA must still run tests one device, operating system, browser, and viewport size at a time. All the tools that provide test scaling still require validation one-at-a-time, either because tools ignore rendering or flag too many erroneous visual differences.
Until Applitools introduced Visual AI testing with Ultrafast Grid.
A Short History of Developer Standards

1999 – Two decades ago, developers built applications for the two browsers that mattered – Netscape Navigator and Microsoft Internet Explorer. Each had its idiosyncrasies and new features. App developers wrote for the mean behavior of both. Windows dominated the desktop, although the new iMac and PowerMac models had begun to reinvigorate Apple. Because rendering mattered, QA engineers tested web pages against IE on Windows, then Netscape on Windows. QA did lots of testing to ensure that custom behavior ran on each platform correctly.

2009 – A decade later, Windows still dominated the desktop, and Internet Explorer still dominated browser use – though Mozilla Firefox also had widespread use. Google Chrome, released in 2008, began to gain traction. More importantly, the iPhone introduced mobile Safari in 2007, while Android introduced mobile Chrome in 2008. Developers built client-side behavior in Java, Flash, and a range of other tools – hoping they could run across all those platforms.

2019 – Today, apps run on mobile devices, laptops, and large 4K screens. Software packages and tools like React make it easy to develop in this fashion. Users select and switch easily among Chrome, Firefox, Safari, and Microsoft Edge. With HTML 5, CSS, and JavaScript standards, your developers can code once and have a high degree of confidence that the app they’re writing will work on all those different platforms, browsers, and viewport sizes.
Until they don’t. Why not? Rendering differences is the most common culprit. All parties agree on the standards – just the rendering engines behave slightly differently. But, how do you discover the differences? You have to test them.
Which, of course, is where you come in. Feeling completely torn apart. Your development teams feel freed by the standards. You have to prove them right – or find the holes in the code they have written.
No Gains in QA Productivity

Sadly, while standards have liberated developers from considering browsers, operating systems, and viewport sizes, QA must wade through each. Rendering, the step of visually representing HTML + CSS + JavaScript, differs from browser engine to browser engine. You may have already experienced the issues – differences in browser rendering behavior can have large impacts on app presentation.
Effectively, development assumes a one-to-many development process. Development tools can help speed the process for developers. Developers may spot-check behaviors between different devices – like comparing mobile versus desktop behavior. But, in most cases, developers leave the brute-force testing of multiple target destinations to the QA team. Developers reason that they’re building behavior and using standards – so they’re done.
That leaves you, the tester, in a world of pain. How do you ensure proper behavior? Where are your “one-to-many” tools that let you rapidly test the behavior of this app across all these different platforms?
Legacy Approaches Balance QA Productivity and Coverage
Legacy test one-at-a-time approaches are the limit to QA productivity. To gain QA efficiency, teams trade off coverage and effort. Most QA teams use one of these three approaches to test their apps across multiple devices, browsers, operating systems and viewport sizes:
- Target The Mean
- Spot check
- Brute force
Let’s look at these approaches and their pitfalls.
Target The Mean
If your organization targets the mean, it’s because speed has become your prime driver. You will test behavior on a single platform or a combination of known priority targets that make up the bulk of your base. You’re willing to live with untested platforms, browsers, and viewport sizes because testing would slow you down. This approach recognizes the limits of legacy QA productivity to provide broad coverage. Represent the mean user and move on.
Targeting the mean leaves your teams with a false set of confidence – in part because how you test is just as important as what you test. If you encounter rendering differences, do your tools bring those differences to your attention? Or, are you simply testing the resulting HTML output reported by different browsers? If you are guilty of functional test myopia, are your tools capable of reporting unexpected rendering behavior?
If you are using a DOM and pixel checker, you can uncover visual differences – often with an unacceptable rate of indicated errors to investigate that turn out not to be errors. In some cases, pixel differences are not visible and would be ignored by a user. In some cases, valid DOM differences are due to app changes and again have no impact on a user. These false-positive errors reduce the efficacy of these tools.
Alternatively, you can use an automated visual comparison tool that uses Visual AI technology. Visual AI technology – the same technology used in facial recognition and self-driving vehicles, has much greater accuracy for this purpose. Do you have a tool that uses Visual AI technology?
Spot Check
The next approach, spot check, involves selective testing of specific platforms, often by manual testers. When you use spot check, you present the images of the app pages of interest on specific platforms for testers to evaluate. Spot Check is like the cartoon “spot the difference”, with the tester playing the role of difference spotter.
Using manual testing for Spot Check has two downsides since its efficacy depends on individuals to exercise the app and look for differences. The first downside is inconsistency – individuals can exercise the app differently and not see the same behavior. For example, if the difference of interest is not on the screen of the app, does the tester scroll down to compare the entire page? The second downside is accuracy – as individuals must highlight differences between pages.
Automated tools can help improve both consistency and accuracy for Spot Check. Small differences won’t be overlooked. Full page differences can be compared and don’t need the tester to scroll and compare. But, depending on the technology you use, you could be inundated with alerts that are false positives. Again, you need something that has high accuracy and uses Visual AI technology.
Brute Force
The Brute Force test method tests everything – all the relevant devices, browsers, and operating systems. There are companies that provide this kind of test environment and report results to you.
For the most part, these systems give you peace-of-mind that your app behavior will repeat from platform to platform. But, what do these Brute Force systems actually test?
If all you are doing is running HTML stimulus through Selenium and asserting results in the output DOM through TestNG (or whatever is your favorite functional test tool), you are really trying to ensure that your server gives you repeatable output for stimulus run across multiple browsers. You might get peace-of-mind. But, are you expecting any differences?
Realistically, no. If you apply the same commands in a repeated fashion to a server via a browser, do you ever expect the response HTML to differ?
Applitools Ultrafast Grid For QA Productivity
If you want to cover the range of devices, operating systems, browsers your customers could use, think differently. Why not realize:
- Apply a test to a server with inputs in an identical sequence and measure the outputs. Any differences you spot in the output DOM point to server-level differences that point to server code.
- Once you have the output DOM, just render the DOM against target browsers – you don’t need to rerun it on the server.
- Use a tool to measure and compare visual output – and gain productivity.
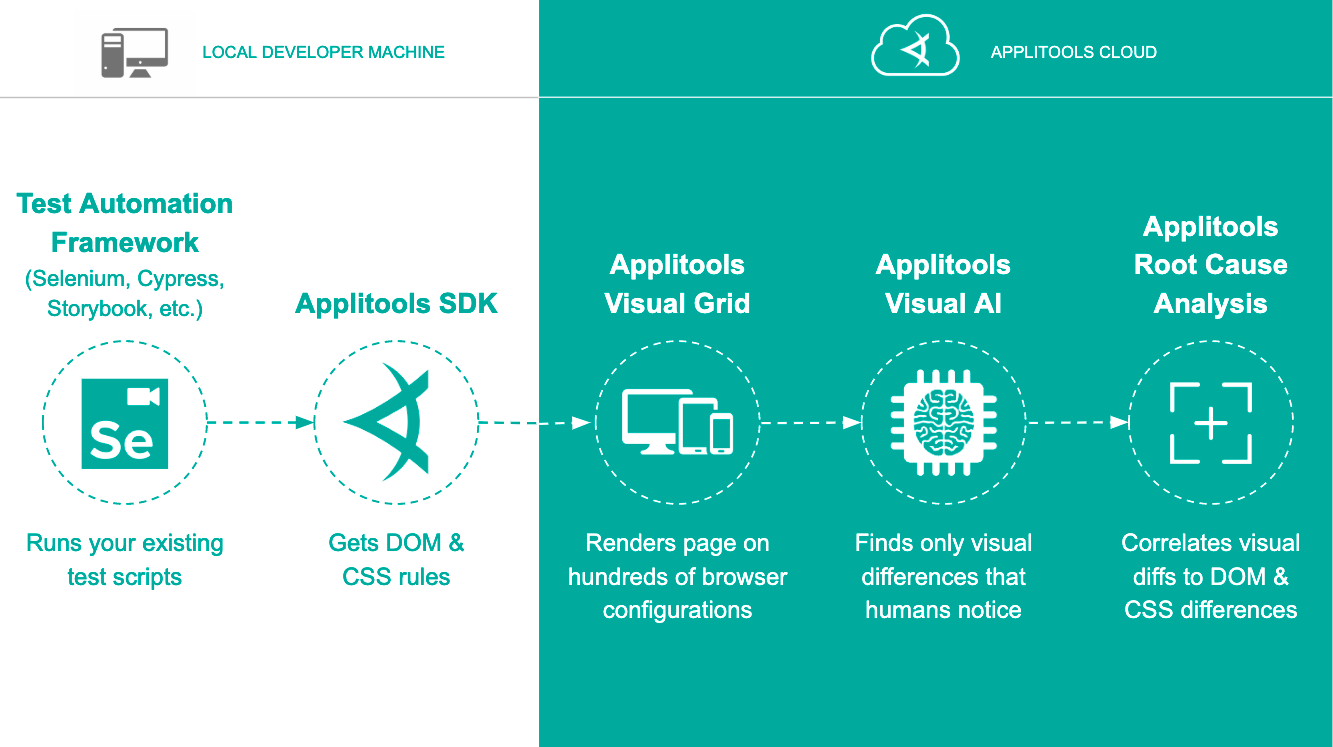
Applitools came to this realization in the development of our Ultrafast Grid. To test dozens of combinations of devices, operating systems, browsers, and viewport sizes, you don’t need to run a test of the servers on each platform of interest. You need to render the output DOM on each of those devices and compare that output to a previous run on that device. If the outputs are the same – you report no change. When you identify a change, and it’s expected, you update your app run to reflect the change. When you identify a change in error, report it back to the developer.
Applitools Eyes provides this kind of capability for a single device, browser, operating system, and viewport size. With Ultrafast Grid, Applitools Eyes gives you the power to extend one test across all the combinations of device/browser/operating system/viewport size that you desire. Because Applitools takes that initial output DOM and re-renders it for you on those other targets, Applitools takes the brute activity out of brute force. And, because Applitools Ultrafast Grid uses Visual AI, it highlights only the differences that users would notice.
Ultrafast Grid For Coverage and Accuracy
If you are looking to test across a range of devices that match what your users might experience, you can:
- Limit yourself to what you think your users will try
- Surprise your developers and try some things you think they didn’t consider
- Run a bunch of tests that make you feel good about coverage
Or, you can consider using Applitools Eyes with Applitools Ultrafast Grid – an approach that gives you both coverage of test conditions as well as the ability to run those tests on all the target platforms that you think matter to your customers.
For More Information
- Web Page Applitools Ultrafast Grid
- Blog: How I ran 372 cross-browser tests in under 3 minutes
- Blog: How I ran 100 UI tests in just 20 seconds
- Documentation: Read about adding Ultrafast Grid to your existing tests
- Visit the Automated Visual Testing Course on Test Automation University
- Blog: How Do I Validate Visually?
- Sign up for a free Applitools account
- Request an Applitools Demo
- Visit the Applitools Tutorials